%pip install -q validmindNote: you may need to restart the kernel to use updated packages.As a model developer, learn how the end-to-end documentation process works based on common scenarios you encounter in model development settings.
As a prerequisite, a model documentation template must be available on the ValidMind Platform. You can view the available templates to see what templates been set up for your organization.
This notebook uses a binary classification model as an example, but the same principles shown here apply to other model types.
1. Initializing the ValidMind Library
The ValidMind Library provides a rich collection of documentation tools and test suites, from documenting descriptions of datasets to validation and testing of models using a variety of open-source testing frameworks.
2. Start the model development process with raw data, run out-of-the box tests, and add evidence to model documentation
Learn how to access ValidMind’s test repository of individual tests that you will use as building blocks to ensure a model is being built appropriately. The goal is to show how to run tests, investigate results, and add tests results or evidence to the documentation.
For a full list of out-of-the-box tests, see Test descriptions or try the interactive Test sandbox.
3. Implementing custom tests
Usually, model developers have their own custom tests and it is important to include this within the model documentation. We will show you how to include custom tests and then how they can be added to documentation as additional evidence.
4. Finalize testing and documentation
Learn how you can ensure that model documentation includes custom tests and how to make test configuration changes that apply to all tests in the model documentation template. At the end of this section you should have a fully documented model ready for review.
ValidMind is a suite of tools for managing model risk, including risk associated with AI and statistical models. You use the ValidMind Library to automate documentation and validation tests, and then use the ValidMind Platform to collaborate on model documentation. Together, these products simplify model risk management, facilitate compliance with regulations and institutional standards, and enhance collaboration between yourself and model validators.
This notebook assumes you have basic familiarity with Python, including an understanding of how functions work. If you are new to Python, you can still run the notebook but we recommend further familiarizing yourself with the language.
If you encounter errors due to missing modules in your Python environment, install the modules with pip install, and then re-run the notebook. For more help, refer to Installing Python Modules.
If you haven’t already seen our Get started with the ValidMind Library, we recommend you explore the available resources for developers at some point. There, you can learn more about documenting models, find code samples, or read our developer reference.
Model documentation: A structured and detailed record pertaining to a model, encompassing key components such as its underlying assumptions, methodologies, data sources, inputs, performance metrics, evaluations, limitations, and intended uses. It serves to ensure transparency, adherence to regulatory requirements, and a clear understanding of potential risks associated with the model’s application.
Documentation template: Functions as a test suite and lays out the structure of model documentation, segmented into various sections and sub-sections. Documentation templates define the structure of your model documentation, specifying the tests that should be run, and how the results should be displayed.
Tests: A function contained in the ValidMind Library, designed to run a specific quantitative test on the dataset or model. Tests are the building blocks of ValidMind, used to evaluate and document models and datasets, and can be run individually or as part of a suite defined by your model documentation template.
Custom tests: Custom tests are functions that you define to evaluate your model or dataset. These functions can be registered via the ValidMind Library to be used with the ValidMind Platform.
Inputs: Objects to be evaluated and documented in the ValidMind Library. They can be any of the following:
vm.init_model().vm.init_dataset().Parameters: Additional arguments that can be passed when running a ValidMind test, used to pass additional information to a test, customize its behavior, or provide additional context.
Outputs: Custom tests can return elements like tables or plots. Tables may be a list of dictionaries (each representing a row) or a pandas DataFrame. Plots may be matplotlib or plotly figures.
Test suites: Collections of tests designed to run together to automate and generate model documentation end-to-end for specific use-cases.
Example: the classifier_full_suite test suite runs tests from the tabular_dataset and classifier test suites to fully document the data and model sections for binary classification model use-cases.
Please note the following recommended Python versions to use:
To install the library:
%pip install -q validmindNote: you may need to restart the kernel to use updated packages.ValidMind generates a unique code snippet for each registered model to connect with your developer environment. You initialize the ValidMind Library with this code snippet, which ensures that your documentation and tests are uploaded to the correct model when you run the notebook.
Get your code snippet:
In a browser, log in to ValidMind.
In the left sidebar, navigate to Model Inventory and click + Register new model.
Enter the model details and click Continue. (Need more help?)
For example, to register a model for use with this notebook, select:
Binary classificationMarketing/Sales - Attrition/Churn ManagementYou can fill in other options according to your preference.
Go to Getting Started and click Copy snippet to clipboard.
Next, replace this placeholder with your own code snippet:
# Load your model identifier credentials from an `.env` file
%load_ext dotenv
%dotenv .env
# Or replace with your code snippet
import validmind as vm
vm.init(
# api_host="...",
# api_key="...",
# api_secret="...",
# model="...",
)2024-11-26 20:18:21,654 - INFO(validmind.api_client): 🎉 Connected to ValidMind!
📊 Model: [ValidMind Academy] Introduction for Model Developers (ID: cm3qekmzf00j62bidcauyqaj7)
📁 Document Type: model_documentationLet’s verify that you have connected to ValidMind and that the appropriate template is selected. A template predefines sections for your model documentation and provides a general outline to follow, making the documentation process much easier.
You will upload documentation and test results for this template later on. For now, take a look at the structure that the template provides with the vm.preview_template() function from the ValidMind library and note the empty sections:
vm.preview_template()Before learning how to run tests, let’s explore the list of all available tests in the ValidMind Library. You can see that the documentation template for this model has references to some of the test IDs listed below.
vm.tests.list_tests()As of langchain-core 0.3.0, LangChain uses pydantic v2 internally. The langchain_core.pydantic_v1 module was a compatibility shim for pydantic v1, and should no longer be used. Please update the code to import from Pydantic directly.
For example, replace imports like: `from langchain_core.pydantic_v1 import BaseModel`
with: `from pydantic import BaseModel`
or the v1 compatibility namespace if you are working in a code base that has not been fully upgraded to pydantic 2 yet. from pydantic.v1 import BaseModel
As of langchain-core 0.3.0, LangChain uses pydantic v2 internally. The langchain.pydantic_v1 module was a compatibility shim for pydantic v1, and should no longer be used. Please update the code to import from Pydantic directly.
For example, replace imports like: `from langchain.pydantic_v1 import BaseModel`
with: `from pydantic import BaseModel`
or the v1 compatibility namespace if you are working in a code base that has not been fully upgraded to pydantic 2 yet. from pydantic.v1 import BaseModel
| ID | Name | Description | Required Inputs | Params |
|---|---|---|---|---|
| validmind.ongoing_monitoring.PredictionAcrossEachFeature | Prediction Across Each Feature | Assesses differences in model predictions across individual features between reference and monitoring datasets... | ['datasets', 'model'] | {} |
| validmind.ongoing_monitoring.TargetPredictionDistributionPlot | Target Prediction Distribution Plot | Assesses differences in prediction distributions between a reference dataset and a monitoring dataset to identify... | ['datasets', 'model'] | {} |
| validmind.ongoing_monitoring.FeatureDrift | Feature Drift | Evaluates changes in feature distribution over time to identify potential model drift.... | ['datasets'] | {'bins': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9], 'feature_columns': None} |
| validmind.ongoing_monitoring.PredictionCorrelation | Prediction Correlation | Assesses correlation changes between model predictions from reference and monitoring datasets to detect potential... | ['datasets', 'model'] | {} |
| validmind.model_validation.BertScore | Bert Score | Assesses the quality of machine-generated text using BERTScore metrics and visualizes results through histograms... | ['dataset', 'model'] | {} |
| validmind.model_validation.RougeScore | Rouge Score | Assesses the quality of machine-generated text using ROUGE metrics and visualizes the results to provide... | ['dataset', 'model'] | {'metric': 'rouge-1'} |
| validmind.model_validation.ModelMetadata | Model Metadata | Compare metadata of different models and generate a summary table with the results.... | ['model'] | {} |
| validmind.model_validation.MeteorScore | Meteor Score | Assesses the quality of machine-generated translations by comparing them to human-produced references using the... | ['dataset', 'model'] | {} |
| validmind.model_validation.TimeSeriesPredictionWithCI | Time Series Prediction With CI | Assesses predictive accuracy and uncertainty in time series models, highlighting breaches beyond confidence... | ['dataset', 'model'] | {'confidence': 0.95} |
| validmind.model_validation.TokenDisparity | Token Disparity | Evaluates the token disparity between reference and generated texts, visualizing the results through histograms and... | ['dataset', 'model'] | {} |
| validmind.model_validation.FeaturesAUC | Features AUC | Evaluates the discriminatory power of each individual feature within a binary classification model by calculating... | ['model', 'dataset'] | {'fontsize': 12, 'figure_height': 500} |
| validmind.model_validation.RegressionResidualsPlot | Regression Residuals Plot | Evaluates regression model performance using residual distribution and actual vs. predicted plots.... | ['model', 'dataset'] | {'bin_size': 0.1} |
| validmind.model_validation.TimeSeriesPredictionsPlot | Time Series Predictions Plot | Plot actual vs predicted values for time series data and generate a visual comparison for the model.... | ['dataset', 'model'] | {} |
| validmind.model_validation.ModelPredictionResiduals | Model Prediction Residuals | Assesses normality and behavior of residuals in regression models through visualization and statistical tests.... | ['dataset', 'model'] | {'nbins': 100, 'p_value_threshold': 0.05, 'start_date': None, 'end_date': None} |
| validmind.model_validation.BleuScore | Bleu Score | Evaluates the quality of machine-generated text using BLEU metrics and visualizes the results through histograms... | ['dataset', 'model'] | {} |
| validmind.model_validation.ClusterSizeDistribution | Cluster Size Distribution | Assesses the performance of clustering models by comparing the distribution of cluster sizes in model predictions... | ['model', 'dataset'] | {} |
| validmind.model_validation.ToxicityScore | Toxicity Score | Assesses the toxicity levels of texts generated by NLP models to identify and mitigate harmful or offensive content.... | ['dataset', 'model'] | {} |
| validmind.model_validation.TimeSeriesR2SquareBySegments | Time Series R2 Square By Segments | Evaluates the R-Squared values of regression models over specified time segments in time series data to assess... | ['dataset', 'model'] | {'segments': None} |
| validmind.model_validation.RegardScore | Regard Score | Assesses the sentiment and potential biases in text generated by NLP models by computing and visualizing regard... | ['dataset', 'model'] | {} |
| validmind.model_validation.ContextualRecall | Contextual Recall | Evaluates a Natural Language Generation model's ability to generate contextually relevant and factually correct... | ['dataset', 'model'] | {} |
| validmind.model_validation.sklearn.RegressionPerformance | Regression Performance | Compares and evaluates the performance of multiple regression models using five different metrics: MAE, MSE, RMSE,... | ['dataset', 'model'] | {} |
| validmind.model_validation.sklearn.WeakspotsDiagnosis | Weakspots Diagnosis | Identifies and visualizes weak spots in a machine learning model's performance across various sections of the... | ['model', 'datasets'] | {'features_columns': None, 'thresholds': {'accuracy': 0.75, 'precision': 0.5, 'recall': 0.5, 'f1': 0.7}} |
| validmind.model_validation.sklearn.PopulationStabilityIndex | Population Stability Index | Assesses the Population Stability Index (PSI) to quantify the stability of an ML model's predictions across... | ['model', 'datasets'] | {'num_bins': 10, 'mode': 'fixed'} |
| validmind.model_validation.sklearn.MinimumF1Score | Minimum F1 Score | Assesses if the model's F1 score on the validation set meets a predefined minimum threshold, ensuring balanced... | ['model', 'dataset'] | {'min_threshold': 0.5} |
| validmind.model_validation.sklearn.FeatureImportance | Feature Importance | Compute feature importance scores for a given model and generate a summary table... | ['dataset', 'model'] | {'num_features': 3} |
| validmind.model_validation.sklearn.OverfitDiagnosis | Overfit Diagnosis | Assesses potential overfitting in a model's predictions, identifying regions where performance between training and... | ['model', 'datasets'] | {'metric': None, 'cut_off_threshold': 0.04} |
| validmind.model_validation.sklearn.RobustnessDiagnosis | Robustness Diagnosis | Assesses the robustness of a machine learning model by evaluating performance decay under noisy conditions.... | ['model', 'datasets'] | {'metric': None, 'scaling_factor_std_dev_list': [0.1, 0.2, 0.3, 0.4, 0.5], 'performance_decay_threshold': 0.05} |
| validmind.model_validation.sklearn.TrainingTestDegradation | Training Test Degradation | Tests if model performance degradation between training and test datasets exceeds a predefined threshold.... | ['model', 'datasets'] | {'metrics': ['accuracy', 'precision', 'recall', 'f1'], 'max_threshold': 0.1} |
| validmind.model_validation.sklearn.SHAPGlobalImportance | SHAP Global Importance | Evaluates and visualizes global feature importance using SHAP values for model explanation and risk identification.... | ['model', 'dataset'] | {'kernel_explainer_samples': 10, 'tree_or_linear_explainer_samples': 200, 'class_of_interest': None} |
| validmind.model_validation.sklearn.FowlkesMallowsScore | Fowlkes Mallows Score | Evaluates the similarity between predicted and actual cluster assignments in a model using the Fowlkes-Mallows... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.SilhouettePlot | Silhouette Plot | Calculates and visualizes Silhouette Score, assessing the degree of data point suitability to its cluster in ML... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.AdjustedMutualInformation | Adjusted Mutual Information | Evaluates clustering model performance by measuring mutual information between true and predicted labels, adjusting... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.HomogeneityScore | Homogeneity Score | Assesses clustering homogeneity by comparing true and predicted labels, scoring from 0 (heterogeneous) to 1... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.VMeasure | V Measure | Evaluates homogeneity and completeness of a clustering model using the V Measure Score.... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.PrecisionRecallCurve | Precision Recall Curve | Evaluates the precision-recall trade-off for binary classification models and visualizes the Precision-Recall curve.... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.ConfusionMatrix | Confusion Matrix | Evaluates and visually represents the classification ML model's predictive performance using a Confusion Matrix... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.MinimumROCAUCScore | Minimum ROCAUC Score | Validates model by checking if the ROC AUC score meets or surpasses a specified threshold.... | ['model', 'dataset'] | {'min_threshold': 0.5} |
| validmind.model_validation.sklearn.ClusterPerformanceMetrics | Cluster Performance Metrics | Evaluates the performance of clustering machine learning models using multiple established metrics.... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.ModelsPerformanceComparison | Models Performance Comparison | Evaluates and compares the performance of multiple Machine Learning models using various metrics like accuracy,... | ['dataset', 'models'] | {'average': 'macro'} |
| validmind.model_validation.sklearn.RegressionR2SquareComparison | Regression R2 Square Comparison | Compares R-Squared and Adjusted R-Squared values for different regression models across multiple datasets to assess... | ['datasets', 'models'] | {} |
| validmind.model_validation.sklearn.RegressionR2Square | Regression R2 Square | Assesses the overall goodness-of-fit of a regression model by evaluating R-squared (R2) and Adjusted R-squared (Adj... | ['dataset', 'model'] | {} |
| validmind.model_validation.sklearn.ClusterPerformance | Cluster Performance | Evaluates and compares a clustering model's performance on training and testing datasets using multiple defined... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.ROCCurve | ROC Curve | Evaluates binary classification model performance by generating and plotting the Receiver Operating Characteristic... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.HyperParametersTuning | Hyper Parameters Tuning | Exerts exhaustive grid search to identify optimal hyperparameters for the model, improving performance.... | ['model', 'dataset'] | {'param_grid': None, 'scoring': None} |
| validmind.model_validation.sklearn.AdjustedRandIndex | Adjusted Rand Index | Measures the similarity between two data clusters using the Adjusted Rand Index (ARI) metric in clustering machine... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.CompletenessScore | Completeness Score | Evaluates a clustering model's capacity to categorize instances from a single class into the same cluster.... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.RegressionErrors | Regression Errors | Assesses the performance and error distribution of a regression model using various error metrics.... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.KMeansClustersOptimization | K Means Clusters Optimization | Optimizes the number of clusters in K-means models using Elbow and Silhouette methods.... | ['model', 'dataset'] | {'n_clusters': None} |
| validmind.model_validation.sklearn.ClassifierPerformance | Classifier Performance | Evaluates performance of binary or multiclass classification models using precision, recall, F1-Score, accuracy,... | ['model', 'dataset'] | {'average': 'macro'} |
| validmind.model_validation.sklearn.PermutationFeatureImportance | Permutation Feature Importance | Assesses the significance of each feature in a model by evaluating the impact on model performance when feature... | ['model', 'dataset'] | {'fontsize': None, 'figure_height': 1000} |
| validmind.model_validation.sklearn.ClusterCosineSimilarity | Cluster Cosine Similarity | Measures the intra-cluster similarity of a clustering model using cosine similarity.... | ['model', 'dataset'] | {} |
| validmind.model_validation.sklearn.RegressionErrorsComparison | Regression Errors Comparison | Assesses multiple regression error metrics to compare model performance across different datasets, emphasizing... | ['datasets', 'models'] | {} |
| validmind.model_validation.sklearn.MinimumAccuracy | Minimum Accuracy | Checks if the model's prediction accuracy meets or surpasses a specified threshold.... | ['model', 'dataset'] | {'min_threshold': 0.7} |
| validmind.model_validation.ragas.NoiseSensitivity | Noise Sensitivity | Assesses the sensitivity of a Large Language Model (LLM) to noise in retrieved context by measuring how often it... | ['dataset'] | {'answer_column': 'answer', 'contexts_column': 'contexts', 'ground_truth_column': 'ground_truth'} |
| validmind.model_validation.ragas.AspectCritique | Aspect Critique | Evaluates generations against the following aspects: harmfulness, maliciousness,... | ['dataset'] | {'question_column': 'question', 'answer_column': 'answer', 'contexts_column': 'contexts', 'aspects': ['coherence', 'conciseness', 'correctness', 'harmfulness', 'maliciousness'], 'additional_aspects': None} |
| validmind.model_validation.ragas.AnswerCorrectness | Answer Correctness | Evaluates the correctness of answers in a dataset with respect to the provided ground... | ['dataset'] | {'question_column': 'question', 'answer_column': 'answer', 'ground_truth_column': 'ground_truth'} |
| validmind.model_validation.ragas.ContextRecall | Context Recall | Context recall measures the extent to which the retrieved context aligns with the... | ['dataset'] | {'question_column': 'question', 'contexts_column': 'contexts', 'ground_truth_column': 'ground_truth'} |
| validmind.model_validation.ragas.AnswerSimilarity | Answer Similarity | Calculates the semantic similarity between generated answers and ground truths... | ['dataset'] | {'answer_column': 'answer', 'ground_truth_column': 'ground_truth'} |
| validmind.model_validation.ragas.ContextUtilization | Context Utilization | Assesses how effectively relevant context chunks are utilized in generating answers by evaluating their ranking... | ['dataset'] | {'question_column': 'question', 'contexts_column': 'contexts', 'answer_column': 'answer'} |
| validmind.model_validation.ragas.ContextEntityRecall | Context Entity Recall | Evaluates the context entity recall for dataset entries and visualizes the results.... | ['dataset'] | {'contexts_column': 'contexts', 'ground_truth_column': 'ground_truth'} |
| validmind.model_validation.ragas.AnswerRelevance | Answer Relevance | Assesses how pertinent the generated answer is to the given prompt.... | ['dataset'] | {'question_column': 'question', 'contexts_column': 'contexts', 'answer_column': 'answer'} |
| validmind.model_validation.ragas.ContextPrecision | Context Precision | Context Precision is a metric that evaluates whether all of the ground-truth... | ['dataset'] | {'question_column': 'question', 'contexts_column': 'contexts', 'ground_truth_column': 'ground_truth'} |
| validmind.model_validation.ragas.Faithfulness | Faithfulness | Evaluates the faithfulness of the generated answers with respect to retrieved contexts.... | ['dataset'] | {'answer_column': 'answer', 'contexts_column': 'contexts'} |
| validmind.model_validation.statsmodels.RegressionPermutationFeatureImportance | Regression Permutation Feature Importance | Assesses the significance of each feature in a model by evaluating the impact on model performance when feature... | ['model', 'dataset'] | {'fontsize': 12, 'figure_height': 500} |
| validmind.model_validation.statsmodels.RegressionModelSummary | Regression Model Summary | Evaluates regression model performance using metrics including R-Squared, Adjusted R-Squared, MSE, and RMSE.... | ['model', 'dataset'] | {} |
| validmind.model_validation.statsmodels.RegressionModelForecastPlotLevels | Regression Model Forecast Plot Levels | Assesses the alignment between forecasted and observed values in regression models through visual plots, including... | ['models', 'datasets'] | {'transformation': None} |
| validmind.model_validation.statsmodels.KolmogorovSmirnov | Kolmogorov Smirnov | Assesses whether each feature in the dataset aligns with a normal distribution using the Kolmogorov-Smirnov test.... | ['dataset'] | {'dist': 'norm'} |
| validmind.model_validation.statsmodels.CumulativePredictionProbabilities | Cumulative Prediction Probabilities | Visualizes cumulative probabilities of positive and negative classes for both training and testing in logistic... | ['dataset', 'model'] | {'title': 'Cumulative Probabilities'} |
| validmind.model_validation.statsmodels.RegressionFeatureSignificance | Regression Feature Significance | Assesses and visualizes the statistical significance of features in a set of regression models.... | ['model'] | {'fontsize': 10, 'p_threshold': 0.05} |
| validmind.model_validation.statsmodels.RegressionModelForecastPlot | Regression Model Forecast Plot | Generates plots to visually compare the forecasted outcomes of one or more regression models against actual... | ['models', 'datasets'] | {'start_date': None, 'end_date': None} |
| validmind.model_validation.statsmodels.AutoARIMA | Auto ARIMA | Evaluates ARIMA models for time-series forecasting, ranking them using Bayesian and Akaike Information Criteria.... | ['dataset'] | {} |
| validmind.model_validation.statsmodels.DurbinWatsonTest | Durbin Watson Test | Assesses autocorrelation in time series data features using the Durbin-Watson statistic.... | ['dataset', 'model'] | {'threshold': [1.5, 2.5]} |
| validmind.model_validation.statsmodels.Lilliefors | Lilliefors | Assesses the normality of feature distributions in an ML model's training dataset using the Lilliefors test.... | ['dataset'] | {} |
| validmind.model_validation.statsmodels.PredictionProbabilitiesHistogram | Prediction Probabilities Histogram | Assesses the predictive probability distribution for binary classification to evaluate model performance and... | ['dataset', 'model'] | {'title': 'Histogram of Predictive Probabilities'} |
| validmind.model_validation.statsmodels.RegressionModelSensitivityPlot | Regression Model Sensitivity Plot | Assesses the sensitivity of a regression model to changes in independent variables by applying shocks and... | ['models', 'datasets'] | {'transformation': None, 'shocks': [0.1]} |
| validmind.model_validation.statsmodels.GINITable | GINI Table | Evaluates classification model performance using AUC, GINI, and KS metrics for training and test datasets.... | ['dataset', 'model'] | {} |
| validmind.model_validation.statsmodels.RegressionCoeffs | Regression Coeffs | Assesses the significance and uncertainty of predictor variables in a regression model through visualization of... | ['model'] | {} |
| validmind.model_validation.statsmodels.ScorecardHistogram | Scorecard Histogram | The Scorecard Histogram test evaluates the distribution of credit scores between default and non-default instances,... | ['dataset'] | {'title': 'Histogram of Scores', 'score_column': 'score'} |
| validmind.model_validation.embeddings.CosineSimilarityComparison | Cosine Similarity Comparison | Assesses the similarity between embeddings generated by different models using Cosine Similarity, providing both... | ['dataset', 'models'] | {} |
| validmind.model_validation.embeddings.EuclideanDistanceHeatmap | Euclidean Distance Heatmap | Generates an interactive heatmap to visualize the Euclidean distances among embeddings derived from a given model.... | ['dataset', 'model'] | {'title': 'Euclidean Distance Matrix', 'color': 'Euclidean Distance', 'xaxis_title': 'Index', 'yaxis_title': 'Index', 'color_scale': 'Blues'} |
| validmind.model_validation.embeddings.CosineSimilarityHeatmap | Cosine Similarity Heatmap | Generates an interactive heatmap to visualize the cosine similarities among embeddings derived from a given model.... | ['dataset', 'model'] | {'title': 'Cosine Similarity Matrix', 'color': 'Cosine Similarity', 'xaxis_title': 'Index', 'yaxis_title': 'Index', 'color_scale': 'Blues'} |
| validmind.model_validation.embeddings.PCAComponentsPairwisePlots | PCA Components Pairwise Plots | Generates scatter plots for pairwise combinations of principal component analysis (PCA) components of model... | ['dataset', 'model'] | {'n_components': 3} |
| validmind.model_validation.embeddings.StabilityAnalysisSynonyms | Stability Analysis Synonyms | Evaluates the stability of text embeddings models when words in test data are replaced by their synonyms randomly.... | ['model', 'dataset'] | {'probability': 0.02, 'mean_similarity_threshold': 0.7} |
| validmind.model_validation.embeddings.EmbeddingsVisualization2D | Embeddings Visualization2 D | Visualizes 2D representation of text embeddings generated by a model using t-SNE technique.... | ['model', 'dataset'] | {'cluster_column': None, 'perplexity': 30} |
| validmind.model_validation.embeddings.CosineSimilarityDistribution | Cosine Similarity Distribution | Assesses the similarity between predicted text embeddings from a model using a Cosine Similarity distribution... | ['model', 'dataset'] | {} |
| validmind.model_validation.embeddings.StabilityAnalysisTranslation | Stability Analysis Translation | Evaluates robustness of text embeddings models to noise introduced by translating the original text to another... | ['model', 'dataset'] | {'source_lang': 'en', 'target_lang': 'fr', 'mean_similarity_threshold': 0.7} |
| validmind.model_validation.embeddings.StabilityAnalysisKeyword | Stability Analysis Keyword | Evaluates robustness of embedding models to keyword swaps in the test dataset.... | ['model', 'dataset'] | {'keyword_dict': None, 'mean_similarity_threshold': 0.7} |
| validmind.model_validation.embeddings.StabilityAnalysis | Stability Analysis | Assesses the stability of embeddings generated by a model when faced with perturbed input data to ensure robustness... | ['model', 'dataset'] | {'mean_similarity_threshold': 0.7} |
| validmind.model_validation.embeddings.DescriptiveAnalytics | Descriptive Analytics | Evaluates statistical properties of text embeddings in an ML model via mean, median, and standard deviation... | ['model', 'dataset'] | {} |
| validmind.model_validation.embeddings.StabilityAnalysisRandomNoise | Stability Analysis Random Noise | Assesses the robustness of text embeddings models to random noise introduced via text perturbations.... | ['model', 'dataset'] | {'mean_similarity_threshold': 0.7, 'probability': 0.02} |
| validmind.model_validation.embeddings.ClusterDistribution | Cluster Distribution | Assesses the distribution of text embeddings across clusters produced by a model using KMeans clustering.... | ['model', 'dataset'] | {'num_clusters': 5} |
| validmind.model_validation.embeddings.EuclideanDistanceComparison | Euclidean Distance Comparison | Assesses and visualizes the dissimilarity between model embeddings using Euclidean distance, providing insights... | ['dataset', 'models'] | {} |
| validmind.model_validation.embeddings.TSNEComponentsPairwisePlots | TSNE Components Pairwise Plots | Creates scatter plots for pairwise combinations of t-SNE components to visualize embeddings and highlight potential... | ['dataset', 'model'] | {'n_components': 2, 'perplexity': 30, 'title': 't-SNE'} |
| validmind.data_validation.TargetRateBarPlots | Target Rate Bar Plots | Generates bar plots visualizing the default rates of categorical features for a classification machine learning... | ['dataset'] | {'default_column': None, 'columns': None} |
| validmind.data_validation.MissingValuesBarPlot | Missing Values Bar Plot | Assesses the percentage and distribution of missing values in the dataset via a bar plot, with emphasis on... | ['dataset'] | {'threshold': 80, 'fig_height': 600} |
| validmind.data_validation.LJungBox | L Jung Box | Assesses autocorrelations in dataset features by performing a Ljung-Box test on each feature.... | ['dataset'] | {} |
| validmind.data_validation.WOEBinTable | WOE Bin Table | Assesses the Weight of Evidence (WoE) and Information Value (IV) of each feature to evaluate its predictive power... | ['dataset'] | {'breaks_adj': None} |
| validmind.data_validation.RunsTest | Runs Test | Executes Runs Test on ML model to detect non-random patterns in output data sequence.... | ['dataset'] | {} |
| validmind.data_validation.TimeSeriesDescription | Time Series Description | Generates a detailed analysis for the provided time series dataset, summarizing key statistics to identify trends,... | ['dataset'] | {} |
| validmind.data_validation.DescriptiveStatistics | Descriptive Statistics | Performs a detailed descriptive statistical analysis of both numerical and categorical data within a model's... | ['dataset'] | {} |
| validmind.data_validation.SeasonalDecompose | Seasonal Decompose | Assesses patterns and seasonality in a time series dataset by decomposing its features into foundational components.... | ['dataset'] | {'seasonal_model': 'additive'} |
| validmind.data_validation.MissingValues | Missing Values | Evaluates dataset quality by ensuring missing value ratio across all features does not exceed a set threshold.... | ['dataset'] | {'min_threshold': 1} |
| validmind.data_validation.ADF | ADF | Assesses the stationarity of a time series dataset using the Augmented Dickey-Fuller (ADF) test.... | ['dataset'] | {} |
| validmind.data_validation.BoxPierce | Box Pierce | Detects autocorrelation in time-series data through the Box-Pierce test to validate model performance.... | ['dataset'] | {} |
| validmind.data_validation.AutoMA | Auto MA | Automatically selects the optimal Moving Average (MA) order for each variable in a time series dataset based on... | ['dataset'] | {'max_ma_order': 3} |
| validmind.data_validation.ClassImbalance | Class Imbalance | Evaluates and quantifies class distribution imbalance in a dataset used by a machine learning model.... | ['dataset'] | {'min_percent_threshold': 10} |
| validmind.data_validation.AutoStationarity | Auto Stationarity | Automates Augmented Dickey-Fuller test to assess stationarity across multiple time series in a DataFrame.... | ['dataset'] | {'max_order': 5, 'threshold': 0.05} |
| validmind.data_validation.EngleGrangerCoint | Engle Granger Coint | Assesses the degree of co-movement between pairs of time series data using the Engle-Granger cointegration test.... | ['dataset'] | {'threshold': 0.05} |
| validmind.data_validation.DFGLSArch | DFGLS Arch | Assesses stationarity in time series data using the Dickey-Fuller GLS test to determine the order of integration.... | ['dataset'] | {} |
| validmind.data_validation.UniqueRows | Unique Rows | Verifies the diversity of the dataset by ensuring that the count of unique rows exceeds a prescribed threshold.... | ['dataset'] | {'min_percent_threshold': 1} |
| validmind.data_validation.ShapiroWilk | Shapiro Wilk | Evaluates feature-wise normality of training data using the Shapiro-Wilk test.... | ['dataset'] | {} |
| validmind.data_validation.FeatureTargetCorrelationPlot | Feature Target Correlation Plot | Visualizes the correlation between input features and the model's target output in a color-coded horizontal bar... | ['dataset'] | {'fig_height': 600} |
| validmind.data_validation.PearsonCorrelationMatrix | Pearson Correlation Matrix | Evaluates linear dependency between numerical variables in a dataset via a Pearson Correlation coefficient heat map.... | ['dataset'] | {} |
| validmind.data_validation.TimeSeriesOutliers | Time Series Outliers | Identifies and visualizes outliers in time-series data using the z-score method.... | ['dataset'] | {'zscore_threshold': 3} |
| validmind.data_validation.ProtectedClassesDescription | Protected Classes Description | Visualizes the distribution of protected classes in the dataset relative to the target variable... | ['dataset'] | {'protected_classes': None} |
| validmind.data_validation.TimeSeriesDescriptiveStatistics | Time Series Descriptive Statistics | Evaluates the descriptive statistics of a time series dataset to identify trends, patterns, and data quality issues.... | ['dataset'] | {} |
| validmind.data_validation.TimeSeriesHistogram | Time Series Histogram | Visualizes distribution of time-series data using histograms and Kernel Density Estimation (KDE) lines.... | ['dataset'] | {'nbins': 30} |
| validmind.data_validation.RollingStatsPlot | Rolling Stats Plot | Evaluates the stationarity of time series data by plotting its rolling mean and standard deviation over a specified... | ['dataset'] | {'window_size': 12} |
| validmind.data_validation.TabularNumericalHistograms | Tabular Numerical Histograms | Generates histograms for each numerical feature in a dataset to provide visual insights into data distribution and... | ['dataset'] | {} |
| validmind.data_validation.DatasetDescription | Dataset Description | Provides comprehensive analysis and statistical summaries of each field in a machine learning model's dataset.... | ['dataset'] | {} |
| validmind.data_validation.AutoAR | Auto AR | Automatically identifies the optimal Autoregressive (AR) order for a time series using BIC and AIC criteria.... | ['dataset'] | {'max_ar_order': 3} |
| validmind.data_validation.WOEBinPlots | WOE Bin Plots | Generates visualizations of Weight of Evidence (WoE) and Information Value (IV) for understanding predictive power... | ['dataset'] | {'breaks_adj': None, 'fig_height': 600, 'fig_width': 500} |
| validmind.data_validation.HighPearsonCorrelation | High Pearson Correlation | Identifies highly correlated feature pairs in a dataset suggesting feature redundancy or multicollinearity.... | ['dataset'] | {'max_threshold': 0.3} |
| validmind.data_validation.ProtectedClassesDisparity | Protected Classes Disparity | Investigates disparities in model performance across different protected class segments.... | ['dataset', 'model'] | {'protected_classes': None, 'disparity_tolerance': 1.25, 'metrics': ['fnr', 'fpr', 'tpr']} |
| validmind.data_validation.ACFandPACFPlot | AC Fand PACF Plot | Analyzes time series data using Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF) plots to... | ['dataset'] | {} |
| validmind.data_validation.TabularCategoricalBarPlots | Tabular Categorical Bar Plots | Generates and visualizes bar plots for each category in categorical features to evaluate the dataset's composition.... | ['dataset'] | {} |
| validmind.data_validation.HighCardinality | High Cardinality | Assesses the number of unique values in categorical columns to detect high cardinality and potential overfitting.... | ['dataset'] | {'num_threshold': 100, 'percent_threshold': 0.1, 'threshold_type': 'percent'} |
| validmind.data_validation.KPSS | KPSS | Assesses the stationarity of time-series data in a machine learning model using the KPSS unit root test.... | ['dataset'] | {} |
| validmind.data_validation.TimeSeriesFrequency | Time Series Frequency | Evaluates consistency of time series data frequency and generates a frequency plot.... | ['dataset'] | {} |
| validmind.data_validation.PhillipsPerronArch | Phillips Perron Arch | Assesses the stationarity of time series data in each feature of the ML model using the Phillips-Perron test.... | ['dataset'] | {} |
| validmind.data_validation.ScatterPlot | Scatter Plot | Assesses visual relationships, patterns, and outliers among features in a dataset through scatter plot matrices.... | ['dataset'] | {} |
| validmind.data_validation.BivariateScatterPlots | Bivariate Scatter Plots | Generates bivariate scatterplots to visually inspect relationships between pairs of numerical predictor variables... | ['dataset'] | {} |
| validmind.data_validation.AutoSeasonality | Auto Seasonality | Automatically identifies and quantifies optimal seasonality in time series data to improve forecasting model... | ['dataset'] | {'min_period': 1, 'max_period': 4} |
| validmind.data_validation.Duplicates | Duplicates | Tests dataset for duplicate entries, ensuring model reliability via data quality verification.... | ['dataset'] | {'min_threshold': 1} |
| validmind.data_validation.ChiSquaredFeaturesTable | Chi Squared Features Table | Assesses the statistical association between categorical features and a target variable using the Chi-Squared test.... | ['dataset'] | {'p_threshold': 0.05} |
| validmind.data_validation.IQROutliersTable | IQR Outliers Table | Determines and summarizes outliers in numerical features using the Interquartile Range method.... | ['dataset'] | {'threshold': 1.5} |
| validmind.data_validation.TooManyZeroValues | Too Many Zero Values | Identifies numerical columns in a dataset that contain an excessive number of zero values, defined by a threshold... | ['dataset'] | {'max_percent_threshold': 0.03} |
| validmind.data_validation.TimeSeriesMissingValues | Time Series Missing Values | Validates time-series data quality by confirming the count of missing values is below a certain threshold.... | ['dataset'] | {'min_threshold': 1} |
| validmind.data_validation.SpreadPlot | Spread Plot | Assesses potential correlations between pairs of time series variables through visualization to enhance... | ['dataset'] | {} |
| validmind.data_validation.ProtectedClassesCombination | Protected Classes Combination | Visualizes combinations of protected classes and their corresponding error metric differences.... | ['dataset', 'model'] | {'protected_classes': None} |
| validmind.data_validation.Skewness | Skewness | Evaluates the skewness of numerical data in a dataset to check against a defined threshold, aiming to ensure data... | ['dataset'] | {'max_threshold': 1} |
| validmind.data_validation.ProtectedClassesThresholdOptimizer | Protected Classes Threshold Optimizer | Obtains a classifier by applying group-specific thresholds to the provided estimator.... | ['dataset'] | {'pipeline': None, 'protected_classes': None, 'X_train': None, 'y_train': None} |
| validmind.data_validation.IsolationForestOutliers | Isolation Forest Outliers | Detects outliers in a dataset using the Isolation Forest algorithm and visualizes results through scatter plots.... | ['dataset'] | {'random_state': 0, 'contamination': 0.1, 'features_columns': None} |
| validmind.data_validation.IQROutliersBarPlot | IQR Outliers Bar Plot | Visualizes outlier distribution across percentiles in numerical data using the Interquartile Range (IQR) method.... | ['dataset'] | {'threshold': 1.5, 'fig_width': 800} |
| validmind.data_validation.TabularDescriptionTables | Tabular Description Tables | Summarizes key descriptive statistics for numerical, categorical, and datetime variables in a dataset.... | ['dataset'] | {} |
| validmind.data_validation.LaggedCorrelationHeatmap | Lagged Correlation Heatmap | Assesses and visualizes correlation between target variable and lagged independent variables in a time-series... | ['dataset'] | {} |
| validmind.data_validation.TabularDateTimeHistograms | Tabular Date Time Histograms | Generates histograms to provide graphical insight into the distribution of time intervals in a model's datetime... | ['dataset'] | {} |
| validmind.data_validation.TimeSeriesLinePlot | Time Series Line Plot | Generates and analyses time-series data through line plots revealing trends, patterns, anomalies over time.... | ['dataset'] | {} |
| validmind.data_validation.JarqueBera | Jarque Bera | Assesses normality of dataset features in an ML model using the Jarque-Bera test.... | ['dataset'] | {} |
| validmind.data_validation.ZivotAndrewsArch | Zivot Andrews Arch | Evaluates the order of integration and stationarity of time series data using the Zivot-Andrews unit root test.... | ['dataset'] | {} |
| validmind.data_validation.DatasetSplit | Dataset Split | Evaluates and visualizes the distribution proportions among training, testing, and validation datasets of an ML... | ['datasets'] | {} |
| validmind.data_validation.nlp.StopWords | Stop Words | Evaluates and visualizes the frequency of English stop words in a text dataset against a defined threshold.... | ['dataset'] | {'min_percent_threshold': 0.5, 'num_words': 25} |
| validmind.data_validation.nlp.Sentiment | Sentiment | Analyzes the sentiment of text data within a dataset using the VADER sentiment analysis tool.... | ['dataset'] | {} |
| validmind.data_validation.nlp.Hashtags | Hashtags | Assesses hashtag frequency in a text column, highlighting usage trends and potential dataset bias or spam.... | ['dataset'] | {'top_hashtags': 25} |
| validmind.data_validation.nlp.Mentions | Mentions | Calculates and visualizes frequencies of '@' prefixed mentions in a text-based dataset for NLP model analysis.... | ['dataset'] | {'top_mentions': 25} |
| validmind.data_validation.nlp.TextDescription | Text Description | Conducts comprehensive textual analysis on a dataset using NLTK to evaluate various parameters and generate... | ['dataset'] | {'unwanted_tokens': {"''", 'mrs', "'s", ' ', "s'", 's', 'us', 'dollar', 'dr', 'ms', '``', 'mr'}, 'num_top_words': 3, 'lang': 'english'} |
| validmind.data_validation.nlp.Toxicity | Toxicity | Assesses the toxicity of text data within a dataset to visualize the distribution of toxicity scores.... | ['dataset'] | {} |
| validmind.data_validation.nlp.CommonWords | Common Words | Assesses the most frequent non-stopwords in a text column for identifying prevalent language patterns.... | ['dataset'] | {} |
| validmind.data_validation.nlp.LanguageDetection | Language Detection | Assesses the diversity of languages in a textual dataset by detecting and visualizing the distribution of languages.... | ['dataset'] | {} |
| validmind.data_validation.nlp.PolarityAndSubjectivity | Polarity And Subjectivity | Analyzes the polarity and subjectivity of text data within a given dataset to visualize the sentiment distribution.... | ['dataset'] | {} |
| validmind.data_validation.nlp.Punctuations | Punctuations | Analyzes and visualizes the frequency distribution of punctuation usage in a given text dataset.... | ['dataset'] | {} |
| validmind.prompt_validation.Conciseness | Conciseness | Analyzes and grades the conciseness of prompts provided to a Large Language Model.... | ['model.prompt'] | {'min_threshold': 7} |
| validmind.prompt_validation.Robustness | Robustness | Assesses the robustness of prompts provided to a Large Language Model under varying conditions and contexts.... | ['model'] | {'num_tests': 10} |
| validmind.prompt_validation.Delimitation | Delimitation | Evaluates the proper use of delimiters in prompts provided to Large Language Models.... | ['model.prompt'] | {'min_threshold': 7} |
| validmind.prompt_validation.Specificity | Specificity | Evaluates and scores the specificity of prompts provided to a Large Language Model (LLM), based on clarity, detail,... | ['model.prompt'] | {'min_threshold': 7} |
| validmind.prompt_validation.NegativeInstruction | Negative Instruction | Evaluates and grades the use of affirmative, proactive language over negative instructions in LLM prompts.... | ['model.prompt'] | {'min_threshold': 7} |
| validmind.prompt_validation.Bias | Bias | Assesses potential bias in a Large Language Model by analyzing the distribution and order of exemplars in the... | ['model.prompt'] | {'min_threshold': 7} |
| validmind.prompt_validation.Clarity | Clarity | Evaluates and scores the clarity of prompts in a Large Language Model based on specified guidelines.... | ['model.prompt'] | {'min_threshold': 7} |
In this section you learn how to explore the individual tests available in ValidMind and how to run them and change parameters as necessary. You will use a public dataset from Kaggle that models a bank customer churn prediction use case. The target column, Exited has a value of 1 when a customer has churned and 0 otherwise.
You can find more information about this dataset here.
The ValidMind Library provides a wrapper to automatically load the dataset as a Pandas DataFrame object.
from validmind.datasets.classification import customer_churn as demo_dataset
print(
f"Loaded demo dataset with: \n\n\t• Target column: '{demo_dataset.target_column}' \n\t• Class labels: {demo_dataset.class_labels}"
)
raw_df = demo_dataset.load_data()
raw_df.head()Loaded demo dataset with:
• Target column: 'Exited'
• Class labels: {'0': 'Did not exit', '1': 'Exited'}| CreditScore | Geography | Gender | Age | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 619 | France | Female | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 1 | 608 | Spain | Female | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
| 2 | 502 | France | Female | 42 | 8 | 159660.80 | 3 | 1 | 0 | 113931.57 | 1 |
| 3 | 699 | France | Female | 39 | 1 | 0.00 | 2 | 0 | 0 | 93826.63 | 0 |
| 4 | 850 | Spain | Female | 43 | 2 | 125510.82 | 1 | 1 | 1 | 79084.10 | 0 |
Let’s do some data quality assessments by running a few individual tests related to data assessment. You will use the vm.tests.list_tests() function introduced above in combination with vm.tests.list_tags() and vm.tests.list_tasks() to find which prebuilt tests are relevant for data quality assessment.
# Get the list of available tags
sorted(vm.tests.list_tags())['AUC',
'analysis',
'anomaly_detection',
'bias_and_fairness',
'binary_classification',
'categorical_data',
'correlation',
'credit_risk',
'data_distribution',
'data_quality',
'data_validation',
'descriptive_statistics',
'dimensionality_reduction',
'embeddings',
'feature_importance',
'few_shot',
'forecasting',
'frequency_analysis',
'kmeans',
'linear_regression',
'llm',
'logistic_regression',
'metadata',
'model_comparison',
'model_diagnosis',
'model_explainability',
'model_interpretation',
'model_metadata',
'model_performance',
'model_predictions',
'model_selection',
'model_training',
'multiclass_classification',
'nlp',
'numerical_data',
'qualitative',
'rag_performance',
'ragas',
'regression',
'retrieval_performance',
'seasonality',
'senstivity_analysis',
'sklearn',
'stationarity',
'statistical_test',
'statsmodels',
'tabular_data',
'text_data',
'time_series_data',
'unit_root_test',
'visualization',
'zero_shot']# Get the list of available task types
sorted(vm.tests.list_tasks())['classification',
'clustering',
'feature_extraction',
'monitoring',
'nlp',
'regression',
'residual_analysis',
'text_classification',
'text_generation',
'text_qa',
'text_summarization',
'time_series_forecasting',
'visualization']You can pass tags and tasks as parameters to the vm.tests.list_tests() function to filter the tests based on the tags and task types. For example, to find tests related to tabular data quality for classification models, you can call list_tests() like this:
vm.tests.list_tests(task="classification", tags=["tabular_data", "data_quality"])| ID | Name | Description | Required Inputs | Params |
|---|---|---|---|---|
| validmind.data_validation.MissingValuesBarPlot | Missing Values Bar Plot | Assesses the percentage and distribution of missing values in the dataset via a bar plot, with emphasis on... | ['dataset'] | {'threshold': 80, 'fig_height': 600} |
| validmind.data_validation.MissingValues | Missing Values | Evaluates dataset quality by ensuring missing value ratio across all features does not exceed a set threshold.... | ['dataset'] | {'min_threshold': 1} |
| validmind.data_validation.HighPearsonCorrelation | High Pearson Correlation | Identifies highly correlated feature pairs in a dataset suggesting feature redundancy or multicollinearity.... | ['dataset'] | {'max_threshold': 0.3} |
| validmind.data_validation.HighCardinality | High Cardinality | Assesses the number of unique values in categorical columns to detect high cardinality and potential overfitting.... | ['dataset'] | {'num_threshold': 100, 'percent_threshold': 0.1, 'threshold_type': 'percent'} |
| validmind.data_validation.Duplicates | Duplicates | Tests dataset for duplicate entries, ensuring model reliability via data quality verification.... | ['dataset'] | {'min_threshold': 1} |
| validmind.data_validation.Skewness | Skewness | Evaluates the skewness of numerical data in a dataset to check against a defined threshold, aiming to ensure data... | ['dataset'] | {'max_threshold': 1} |
Now, assume we have identified some tests we want to run with regards to the data we are intending to use. The next step is to connect your data with a ValidMind Dataset object. This step is always necessary every time you want to connect a dataset to documentation and produce test results through ValidMind. You only need to do it one time per dataset.
You can initialize a ValidMind dataset object using the init_dataset function from the ValidMind (vm) module.
This function takes a number of arguments:
dataset — the raw dataset that you want to provide as input to testsinput_id - a unique identifier that allows tracking what inputs are used when running each individual testtarget_column — a required argument if tests require access to true values. This is the name of the target column in the dataset# vm_raw_dataset is now a VMDataset object that you can pass to any ValidMind test
vm_raw_dataset = vm.init_dataset(
dataset=raw_df,
input_id="raw_dataset",
target_column="Exited",
)2024-11-26 20:18:26,896 - INFO(validmind.client): Pandas dataset detected. Initializing VM Dataset instance...Individual tests can be easily run by calling the run_test function provided by the validmind.tests module. The function takes the following arguments:
test_id: The ID of the test to run. To find a particular test and get its ID, refer to the explore_tests notebook. Look above for example after running ‘vm.test_suites.describe_suite’ as column ‘Test ID’ will contain the id.params: A dictionary of parameters for the test. These will override any default_params set in the test definition. Refer to the explore_tests notebook to find the default parameters for a test. See below for examples.The inputs expected by a test can also be found in the test definition. Let’s take validmind.data_validation.DescriptiveStatistics as an example. Note that the output of the describe_test() function below shows that this test expects a dataset as input:
vm.tests.describe_test("validmind.data_validation.DescriptiveStatistics")Now, let’s run a few tests to assess the quality of the dataset.
test = vm.tests.run_test(
test_id="validmind.data_validation.DescriptiveStatistics",
inputs={"dataset": vm_raw_dataset},
)test2 = vm.tests.run_test(
test_id="validmind.data_validation.ClassImbalance",
inputs={"dataset": vm_raw_dataset},
params={"min_percent_threshold": 30},
)You can see that the class imbalance test did not pass according to the value of min_percent_threshold we have set. Here is how you can re-run the test on some processed data to address this data quality issue. In this case we apply a very simple rebalancing technique to the dataset.
import pandas as pd
raw_copy_df = raw_df.sample(frac=1) # Create a copy of the raw dataset
# Create a balanced dataset with the same number of exited and not exited customers
exited_df = raw_copy_df.loc[raw_copy_df["Exited"] == 1]
not_exited_df = raw_copy_df.loc[raw_copy_df["Exited"] == 0].sample(n=exited_df.shape[0])
balanced_raw_df = pd.concat([exited_df, not_exited_df])
balanced_raw_df = balanced_raw_df.sample(frac=1, random_state=42)With this new raw dataset, you can re-run the individual test to see if it passes the class imbalance test requirement. Remember to register new VM Dataset object since that is the type of input required by run_test():
# Register new data and now 'balanced_raw_dataset' is the new dataset object of interest
vm_balanced_raw_dataset = vm.init_dataset(
dataset=balanced_raw_df,
input_id="balanced_raw_dataset",
target_column="Exited",
)2024-11-26 20:18:38,997 - INFO(validmind.client): Pandas dataset detected. Initializing VM Dataset instance...test = vm.tests.run_test(
test_id="validmind.data_validation.ClassImbalance",
inputs={"dataset": vm_balanced_raw_dataset},
params={"min_percent_threshold": 30},
)Here is an example for how you can utilize the output from a ValidMind test for futher use, for example, if you want to remove highly correlated features. The example below shows how you can get the list of features with the highest correlation coefficients and use them to reduce the final list of features for modeling.
corr_results = vm.tests.run_test(
test_id="validmind.data_validation.HighPearsonCorrelation",
params={"max_threshold": 0.3},
inputs={"dataset": vm_balanced_raw_dataset},
)Let’s assume we want to remove highly correlated features from the dataset. corr_results is an object of type ThresholdTestResult and we can inspects its individual results to get access to the features that failed the test. In general, all ValidMind tests can return two different types of results:
print(corr_results.test_results)
print("test_name: ", corr_results.test_results.test_name)
print("params: ", corr_results.test_results.params)
print("passed: ", corr_results.test_results.passed)
print("results: ", corr_results.test_results.results)ThresholdTestResults(test_name='validmind.data_validation.HighPearsonCorrelation', ref_id='c0baebd7-6782-431f-a316-1f8cf4510259', params={'max_threshold': 0.3}, passed=False, results=[ThresholdTestResult(values={'correlations': [{'column': 'Exited', 'correlation': 0.3482002451434722}]}, test_name=None, column='Age', passed=False), ThresholdTestResult(values={'correlations': [{'column': 'IsActiveMember', 'correlation': -0.20637758367725134}]}, test_name=None, column='Exited', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': -0.17021005674608633}]}, test_name=None, column='Balance', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'Exited', 'correlation': 0.14294182023187238}]}, test_name=None, column='Balance', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': -0.05543745376078543}]}, test_name=None, column='Exited', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': 0.042868426320605356}]}, test_name=None, column='IsActiveMember', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': -0.03909050179635669}]}, test_name=None, column='Age', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'Balance', 'correlation': 0.03653465624383657}]}, test_name=None, column='Age', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'Exited', 'correlation': -0.028920034740962802}]}, test_name=None, column='CreditScore', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'IsActiveMember', 'correlation': -0.0285962432848536}]}, test_name=None, column='HasCrCard', passed=True)], summary=ResultSummary(results=[ResultTable(data=[{'Columns': '(Age, Exited)', 'Coefficient': 0.3482002451434722, 'Pass/Fail': 'Fail'}, {'Columns': '(Exited, IsActiveMember)', 'Coefficient': -0.20637758367725134, 'Pass/Fail': 'Pass'}, {'Columns': '(Balance, NumOfProducts)', 'Coefficient': -0.17021005674608633, 'Pass/Fail': 'Pass'}, {'Columns': '(Balance, Exited)', 'Coefficient': 0.14294182023187238, 'Pass/Fail': 'Pass'}, {'Columns': '(Exited, NumOfProducts)', 'Coefficient': -0.05543745376078543, 'Pass/Fail': 'Pass'}, {'Columns': '(IsActiveMember, NumOfProducts)', 'Coefficient': 0.042868426320605356, 'Pass/Fail': 'Pass'}, {'Columns': '(Age, NumOfProducts)', 'Coefficient': -0.03909050179635669, 'Pass/Fail': 'Pass'}, {'Columns': '(Age, Balance)', 'Coefficient': 0.03653465624383657, 'Pass/Fail': 'Pass'}, {'Columns': '(CreditScore, Exited)', 'Coefficient': -0.028920034740962802, 'Pass/Fail': 'Pass'}, {'Columns': '(HasCrCard, IsActiveMember)', 'Coefficient': -0.0285962432848536, 'Pass/Fail': 'Pass'}], type='table', metadata=ResultTableMetadata(title='High Pearson Correlation Results for Dataset'))]))
test_name: validmind.data_validation.HighPearsonCorrelation
params: {'max_threshold': 0.3}
passed: False
results: [ThresholdTestResult(values={'correlations': [{'column': 'Exited', 'correlation': 0.3482002451434722}]}, test_name=None, column='Age', passed=False), ThresholdTestResult(values={'correlations': [{'column': 'IsActiveMember', 'correlation': -0.20637758367725134}]}, test_name=None, column='Exited', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': -0.17021005674608633}]}, test_name=None, column='Balance', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'Exited', 'correlation': 0.14294182023187238}]}, test_name=None, column='Balance', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': -0.05543745376078543}]}, test_name=None, column='Exited', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': 0.042868426320605356}]}, test_name=None, column='IsActiveMember', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': -0.03909050179635669}]}, test_name=None, column='Age', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'Balance', 'correlation': 0.03653465624383657}]}, test_name=None, column='Age', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'Exited', 'correlation': -0.028920034740962802}]}, test_name=None, column='CreditScore', passed=True), ThresholdTestResult(values={'correlations': [{'column': 'IsActiveMember', 'correlation': -0.0285962432848536}]}, test_name=None, column='HasCrCard', passed=True)]Let’s inspect the results and extract a list of features that failed the test:
corr_results.test_results.results[ThresholdTestResult(values={'correlations': [{'column': 'Exited', 'correlation': 0.3482002451434722}]}, test_name=None, column='Age', passed=False),
ThresholdTestResult(values={'correlations': [{'column': 'IsActiveMember', 'correlation': -0.20637758367725134}]}, test_name=None, column='Exited', passed=True),
ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': -0.17021005674608633}]}, test_name=None, column='Balance', passed=True),
ThresholdTestResult(values={'correlations': [{'column': 'Exited', 'correlation': 0.14294182023187238}]}, test_name=None, column='Balance', passed=True),
ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': -0.05543745376078543}]}, test_name=None, column='Exited', passed=True),
ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': 0.042868426320605356}]}, test_name=None, column='IsActiveMember', passed=True),
ThresholdTestResult(values={'correlations': [{'column': 'NumOfProducts', 'correlation': -0.03909050179635669}]}, test_name=None, column='Age', passed=True),
ThresholdTestResult(values={'correlations': [{'column': 'Balance', 'correlation': 0.03653465624383657}]}, test_name=None, column='Age', passed=True),
ThresholdTestResult(values={'correlations': [{'column': 'Exited', 'correlation': -0.028920034740962802}]}, test_name=None, column='CreditScore', passed=True),
ThresholdTestResult(values={'correlations': [{'column': 'IsActiveMember', 'correlation': -0.0285962432848536}]}, test_name=None, column='HasCrCard', passed=True)]Remove the highly correlated features and create a new VM dataset object. Note the use of different input_ids. This allows tracking the inputs used when running each individual test.
high_correlation_features = [
result.column
for result in corr_results.test_results.results
if result.passed == False
]
high_correlation_features['Age']# Remove the highly correlated features from the dataset
balanced_raw_no_age_df = balanced_raw_df.drop(columns=high_correlation_features)
# Re-initialize the dataset object
vm_raw_dataset_preprocessed = vm.init_dataset(
dataset=balanced_raw_no_age_df,
input_id="raw_dataset_preprocessed",
target_column="Exited",
)2024-11-26 20:18:46,484 - INFO(validmind.client): Pandas dataset detected. Initializing VM Dataset instance...Re-running the test with the reduced feature set should pass the test. You can also plot the correlation matrix to visualize the new correlation between features:
corr_results = vm.tests.run_test(
test_id="validmind.data_validation.HighPearsonCorrelation",
params={"max_threshold": 0.3},
inputs={"dataset": vm_raw_dataset_preprocessed},
)corr_results = vm.tests.run_test(
test_id="validmind.data_validation.PearsonCorrelationMatrix",
inputs={"dataset": vm_raw_dataset_preprocessed},
)We have now done some analysis on two different datasets and we should able to document why certain things were done to the raw data with testing to support it. Every test result returned by the run_test() function has a .log() method that can be used to log the test results to ValidMind. When logging individual results to ValidMind you need to manually add those results in a specific section of the model documentation.
When using run_documentation_tests(), it’s possible to automatically populate a section with the results of all tests that were registered in the documentation template.
To show how to add individual results to any documentation section, we’re going to populate the entire data_preparation section of the documentation using the clean vm_raw_dataset_preprocessed dataset as input, and then we’re going to document an additional result for the highly correlated dataset vm_balanced_raw_dataset. The following two steps will accomplish this:
run_documentation_tests() using vm_raw_dataset_preprocessed as input. This populates the entire data preparation section for every test that is already part of the documentation template.vm_balanced_raw_dataset (that had a highly correlated Age column) as inputAfter adding the result of step #2 to the documentation you will be able to explain the changes made to the raw data by editing the default description of the test result within the ValidMind Platform.
run_documentation_tests() using vm_raw_dataset_preprocessed as inputrun_documentation_tests() allows you to run multiple tests at once and log the results to the documentation. The function takes the following arguments:
inputs: any inputs to be passed to the testsconfig: a dictionary <test_id>:<test_config> that allows configuring each test individually. Each test config has the following form:
params: individual test parametersinputs: individual test inputs. When passed, this overrides any inputs passed from the run_documentation_tests() functiontest_config = {
"validmind.data_validation.ClassImbalance": {
"params": {"min_percent_threshold": 30},
},
"validmind.data_validation.HighPearsonCorrelation": {
"params": {"max_threshold": 0.3},
},
}
tests_suite = vm.run_documentation_tests(
inputs={
"dataset": vm_raw_dataset_preprocessed,
},
config=test_config,
section=["data_preparation"],
)You can now visit the documentation page for the model you connected to at the beginning of this notebook and add a new content block in the relevant section.
To do this, go to the documentation page of your model and navigate to the Data Preparation -> Correlations and Interactions section. Then hover after the “Pearson Correlation Matrix” content block to reveal the + button as shown in the screenshot below.

Click on the + button and select Test-Driven Block. This will open a dialog where you can select Threshold Test as the type of the test-driven content block, and then select High Pearson Correlation Vm Raw Dataset Test. This will show a preview of the result and it should match the results shown above.
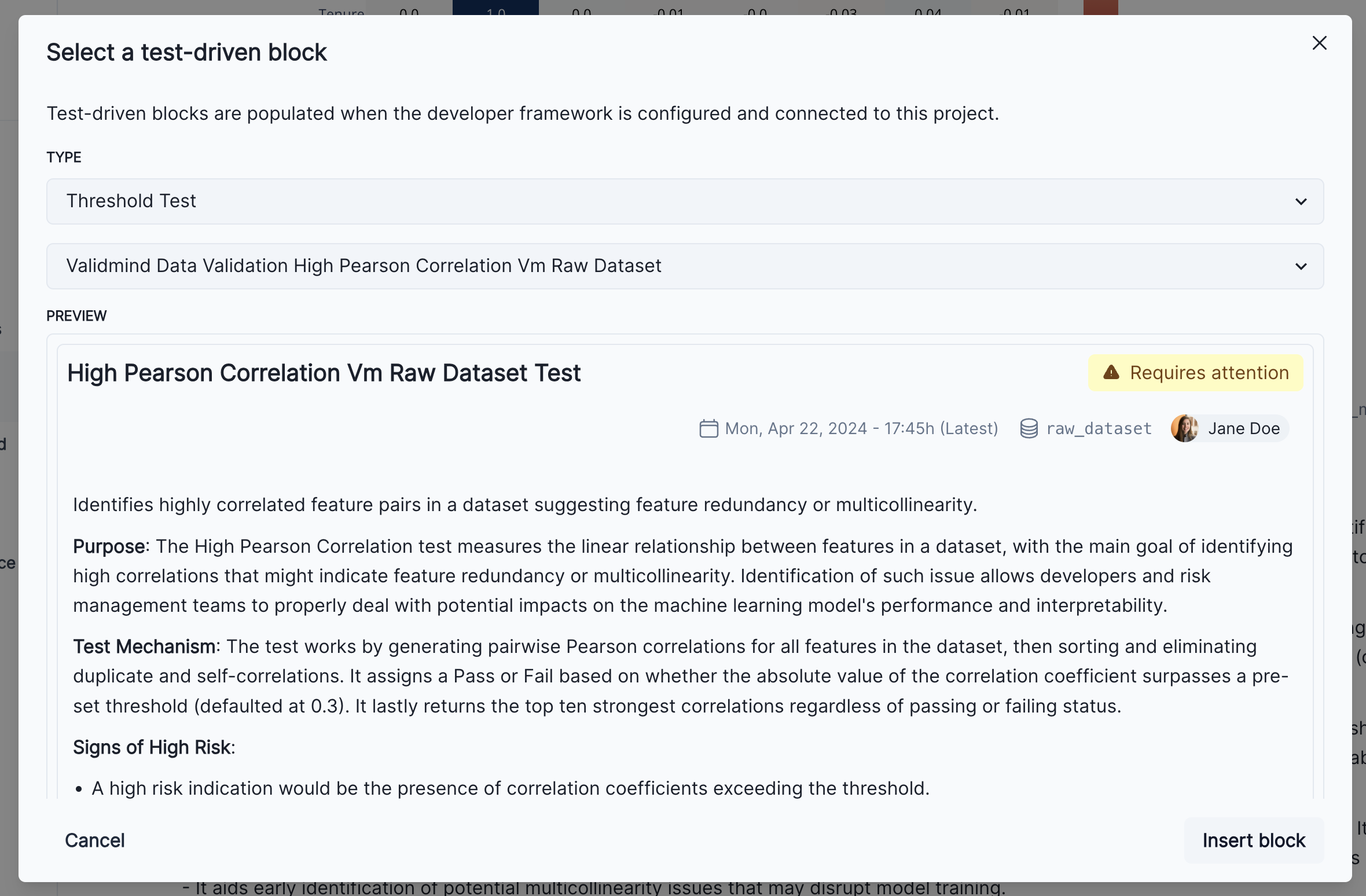
Finally, click on the Insert block button to add the test result to the documentation. You’ll now see two individual results for the high correlation test in the Correlations and Interactions section of the documentation. To finalize the documentation, you can edit the test result’s description block to explain the changes made to the raw data and the reasons behind them as we can see in the screenshot below.
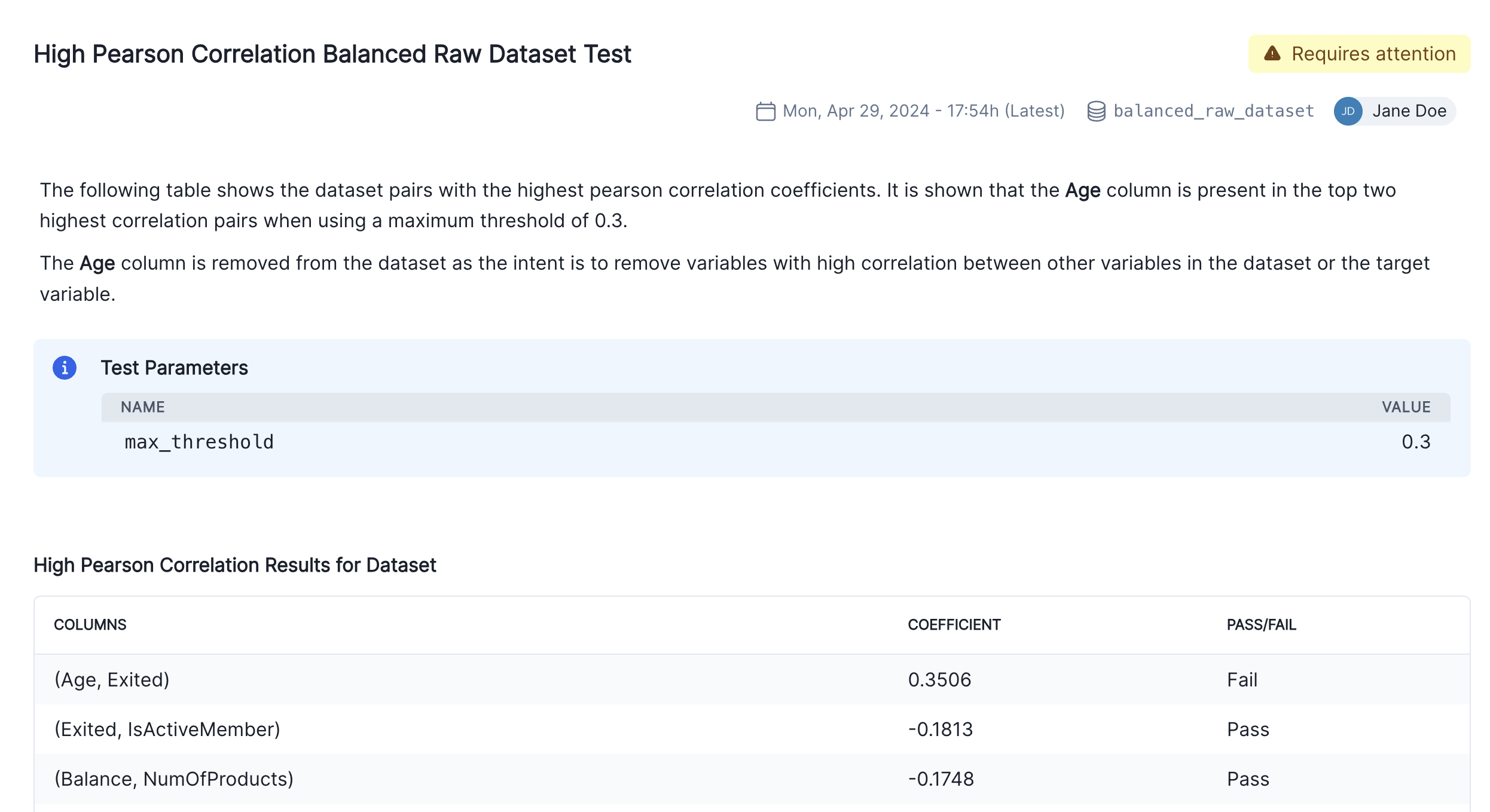
We have focused so far on the data assessment and pre-processing that usually occurs prior to any models being built. Now we are going to assume we have built a model and we want to incorporate some model results in our documentation.
Let’s train a simple logistic regression model on the dataset and evaluate its performance. You will use the LogisticRegression class from the sklearn.linear_model and use ValidMind tests to evaluate the model’s performance.
Before training the model, we need to encode the categorical features in the dataset. You will use the OneHotEncoder class from the sklearn.preprocessing module to encode the categorical features. The categorical features in the dataset are Geography and Gender.
balanced_raw_no_age_df.head()| CreditScore | Geography | Gender | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited | |
|---|---|---|---|---|---|---|---|---|---|---|
| 6816 | 689 | Germany | Male | 2 | 118812.5 | 2 | 0 | 0 | 31121.42 | 0 |
| 5298 | 713 | France | Female | 8 | 0.0 | 1 | 1 | 1 | 16403.41 | 0 |
| 1983 | 567 | France | Female | 4 | 0.0 | 2 | 0 | 1 | 121053.19 | 0 |
| 899 | 513 | France | Male | 8 | 0.0 | 1 | 1 | 0 | 76640.29 | 1 |
| 7180 | 547 | Germany | Female | 1 | 142703.4 | 1 | 1 | 0 | 86207.49 | 1 |
balanced_raw_no_age_df = pd.get_dummies(
balanced_raw_no_age_df, columns=["Geography", "Gender"], drop_first=True
)
balanced_raw_no_age_df.head()| CreditScore | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited | Geography_Germany | Geography_Spain | Gender_Male | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 6816 | 689 | 2 | 118812.5 | 2 | 0 | 0 | 31121.42 | 0 | True | False | True |
| 5298 | 713 | 8 | 0.0 | 1 | 1 | 1 | 16403.41 | 0 | False | False | False |
| 1983 | 567 | 4 | 0.0 | 2 | 0 | 1 | 121053.19 | 0 | False | False | False |
| 899 | 513 | 8 | 0.0 | 1 | 1 | 0 | 76640.29 | 1 | False | False | True |
| 7180 | 547 | 1 | 142703.4 | 1 | 1 | 0 | 86207.49 | 1 | True | False | False |
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# Split the input and target variables
X = balanced_raw_no_age_df.drop("Exited", axis=1)
y = balanced_raw_no_age_df["Exited"]
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
)
# Logistic Regression grid params
log_reg_params = {
"penalty": ["l1", "l2"],
"C": [0.001, 0.01, 0.1, 1, 10, 100, 1000],
"solver": ["liblinear"],
}
# Grid search for Logistic Regression
from sklearn.model_selection import GridSearchCV
grid_log_reg = GridSearchCV(LogisticRegression(), log_reg_params)
grid_log_reg.fit(X_train, y_train)
# Logistic Regression best estimator
log_reg = grid_log_reg.best_estimator_The last step for evaluating the model’s performance is to initialize the ValidMind Dataset and Model objects and assign model predictions to each dataset. You will use the init_dataset, init_model and assign_predictions functions to initialize these objects.
train_df = X_train
train_df["Exited"] = y_train
test_df = X_test
test_df["Exited"] = y_test
vm_train_ds = vm.init_dataset(
input_id="train_dataset_final",
dataset=train_df,
target_column="Exited",
)
vm_test_ds = vm.init_dataset(
input_id="test_dataset_final",
dataset=test_df,
target_column="Exited",
)
# Register the model
vm_model = vm.init_model(log_reg, input_id="log_reg_model_v1")2024-11-26 20:19:08,118 - INFO(validmind.client): Pandas dataset detected. Initializing VM Dataset instance...
2024-11-26 20:19:08,252 - INFO(validmind.client): Pandas dataset detected. Initializing VM Dataset instance...Once the model has been registered you can assign model predictions to the training and test datasets. The assign_predictions() method from the Dataset object can link existing predictions to any number of models. If no prediction values are passed, the method will compute predictions automatically:
vm_train_ds.assign_predictions(model=vm_model)
vm_test_ds.assign_predictions(model=vm_model)2024-11-26 20:19:08,479 - INFO(validmind.vm_models.dataset.utils): Running predict_proba()... This may take a while
X does not have valid feature names, but LogisticRegression was fitted with feature names
2024-11-26 20:19:08,482 - INFO(validmind.vm_models.dataset.utils): Done running predict_proba()
2024-11-26 20:19:08,482 - INFO(validmind.vm_models.dataset.utils): Running predict()... This may take a while
X does not have valid feature names, but LogisticRegression was fitted with feature names
2024-11-26 20:19:08,484 - INFO(validmind.vm_models.dataset.utils): Done running predict()
2024-11-26 20:19:08,486 - INFO(validmind.vm_models.dataset.utils): Running predict_proba()... This may take a while
X does not have valid feature names, but LogisticRegression was fitted with feature names
2024-11-26 20:19:08,488 - INFO(validmind.vm_models.dataset.utils): Done running predict_proba()
2024-11-26 20:19:08,488 - INFO(validmind.vm_models.dataset.utils): Running predict()... This may take a while
X does not have valid feature names, but LogisticRegression was fitted with feature names
2024-11-26 20:19:08,489 - INFO(validmind.vm_models.dataset.utils): Done running predict()In this part, we focus on running the tests within the model development section of the model documentation. Only tests associated with this section will be executed, and the corresponding results will be updated in the model documentation. In the example below, you will focus on only running tests for the model development section of the document.
Note the additional config that is passed to run_documentation_tests(). This allows you to override inputs or params in certain tests. In our case, we want to explicitly use the vm_train_ds for the validmind.model_validation.sklearn.ClassifierPerformance:in_sample test, since it’s supposed to run on the training dataset and not the test dataset.
test_config = {
"validmind.model_validation.sklearn.ClassifierPerformance:in_sample": {
"inputs": {
"dataset": vm_train_ds,
"model": vm_model,
},
}
}
results = vm.run_documentation_tests(
section=["model_development"],
inputs={
"dataset": vm_test_ds, # Any test that requires a single dataset will use vm_test_ds
"model": vm_model,
"datasets": (
vm_train_ds,
vm_test_ds,
), # Any test that requires multiple datasets will use vm_train_ds and vm_test_ds
},
config=test_config,
)X does not have valid feature names, but LogisticRegression was fitted with feature names
X does not have valid feature names, but LogisticRegression was fitted with feature names
Using fork() can cause Polars to deadlock in the child process.
In addition, using fork() with Python in general is a recipe for mysterious
deadlocks and crashes.
The most likely reason you are seeing this error is because you are using the
multiprocessing module on Linux, which uses fork() by default. This will be
fixed in Python 3.14. Until then, you want to use the "spawn" context instead.
See https://docs.pola.rs/user-guide/misc/multiprocessing/ for details.
2024-11-26 20:19:10,111 - ERROR(validmind.vm_models.test_suite.test): Failed to run test 'validmind.model_validation.sklearn.SHAPGlobalImportance': (TypeError) loop of ufunc does not support argument 0 of type float which has no callable rint method
2024-11-26 20:19:14,945 - INFO(validmind.tests.model_validation.sklearn.OverfitDiagnosis): Using default classification metric: auc
2024-11-26 20:19:14,945 - INFO(validmind.tests.model_validation.sklearn.OverfitDiagnosis): Using default cut-off threshold of 0.04
2024-11-26 20:19:16,010 - INFO(validmind.tests.model_validation.sklearn.RobustnessDiagnosis): Using default metric (AUC) for robustness diagnosis
2024-11-26 20:19:16,011 - INFO(validmind.tests.model_validation.sklearn.RobustnessDiagnosis): Using default scaling factors for the standard deviation of the noise: [0.1, 0.2, 0.3, 0.4, 0.5]
2024-11-26 20:19:16,012 - INFO(validmind.tests.model_validation.sklearn.RobustnessDiagnosis): Using default performance decay threshold of 0.05This section assumes that model developers already have a repository of custom made tests that they consider critical to include in the documentation. Here we provide details on how to easily integrate custom tests with ValidMind.
For a more in-depth introduction to custom tests, refer to this notebook.
A custom test is any function that takes a set of inputs and parameters as arguments and returns one or more outputs. The function can be as simple or as complex as you need it to be. It can use external libraries, make API calls, or do anything else that you can do in Python. The only requirement is that the function signature and return values can be “understood” and handled by the ValidMind Library. As such, custom tests offer added flexibility by extending the default tests provided by ValidMind, enabling you to document any type of model or use case.
In the following example, you will learn how to implement a custom inline test that calculates the confusion matrix for a binary classification model. You will see that the custom test function is just a regular Python function that can include and require any Python library as you see fit.
NOTE: in the context of Jupyter notebooks, we will use the word inline to refer to functions (or code) defined in the same notebook where they are used (this one) and not in a separate file, as we will see later with test providers.
To understand how to create a custom test from anything, let’s first create a confusion matrix plot using the confusion_matrix function from the sklearn.metrics module.
import matplotlib.pyplot as plt
from sklearn import metrics
# Get the predicted classes
y_pred = log_reg.predict(vm_test_ds.x)
confusion_matrix = metrics.confusion_matrix(y_test, y_pred)
cm_display = metrics.ConfusionMatrixDisplay(
confusion_matrix=confusion_matrix, display_labels=[False, True]
)
cm_display.plot()
We will now create a @vm.test wrapper that will allow you to create a reusable test. Note the following changes in the code below:
confusion_matrix takes two arguments dataset and model. This is a VMDataset and VMModel object respectively.
VMDataset objects allow you to access the dataset’s true (target) values by accessing the .y attribute.VMDataset objects allow you to access the predictions for a given model by accessing the .y_pred() method.sklearn.metrics.confusion_matrix function as we just did above.ConfusionMatrixDisplay.figure_ object - this is important as the ValidMind Library expects the output of the custom test to be a plot or a table.@vm.test decorator is doing the work of creating a wrapper around the function that will allow it to be run by the ValidMind Library. It also registers the test so it can be found by the ID my_custom_tests.ConfusionMatrix (see the section below on how test IDs work in ValidMind and why this format is important)@vm.test("my_custom_tests.ConfusionMatrix")
def confusion_matrix(dataset, model):
"""The confusion matrix is a table that is often used to describe the performance of a classification model on a set of data for which the true values are known.
The confusion matrix is a 2x2 table that contains 4 values:
- True Positive (TP): the number of correct positive predictions
- True Negative (TN): the number of correct negative predictions
- False Positive (FP): the number of incorrect positive predictions
- False Negative (FN): the number of incorrect negative predictions
The confusion matrix can be used to assess the holistic performance of a classification model by showing the accuracy, precision, recall, and F1 score of the model on a single figure.
"""
y_true = dataset.y
y_pred = dataset.y_pred(model=model)
confusion_matrix = metrics.confusion_matrix(y_true, y_pred)
cm_display = metrics.ConfusionMatrixDisplay(
confusion_matrix=confusion_matrix, display_labels=[False, True]
)
cm_display.plot()
plt.close() # close the plot to avoid displaying it
return cm_display.figure_ # return the figure object itselfYou can now run the newly created custom test on both the training and test datasets using the run_test() function:
# Training dataset
result = vm.tests.run_test(
"my_custom_tests.ConfusionMatrix:training_dataset",
inputs={"model": vm_model, "dataset": vm_train_ds},
)# Test dataset
result = vm.tests.run_test(
"my_custom_tests.ConfusionMatrix:test_dataset",
inputs={"model": vm_model, "dataset": vm_test_ds},
)Custom tests can take parameters just like any other function. Let’s modify the confusion_matrix function to take an additional parameter normalize that will allow you to normalize the confusion matrix.
@vm.test("my_custom_tests.ConfusionMatrix")
def confusion_matrix(dataset, model, normalize=False):
"""The confusion matrix is a table that is often used to describe the performance of a classification model on a set of data for which the true values are known.
The confusion matrix is a 2x2 table that contains 4 values:
- True Positive (TP): the number of correct positive predictions
- True Negative (TN): the number of correct negative predictions
- False Positive (FP): the number of incorrect positive predictions
- False Negative (FN): the number of incorrect negative predictions
The confusion matrix can be used to assess the holistic performance of a classification model by showing the accuracy, precision, recall, and F1 score of the model on a single figure.
"""
y_true = dataset.y
y_pred = dataset.y_pred(model=model)
if normalize:
confusion_matrix = metrics.confusion_matrix(y_true, y_pred, normalize="all")
else:
confusion_matrix = metrics.confusion_matrix(y_true, y_pred)
cm_display = metrics.ConfusionMatrixDisplay(
confusion_matrix=confusion_matrix, display_labels=[False, True]
)
cm_display.plot()
plt.close() # close the plot to avoid displaying it
return cm_display.figure_ # return the figure object itselfYou can pass parameters to custom tests by providing a dictionary of parameters to the run_test() function. The parameters will override any default parameters set in the custom test definition. Note that dataset and model are still passed as inputs. Since these are VMDataset or VMModel inputs, they have a special meaning. When declaring a dataset, model, datasets or models argument in a custom test function, the ValidMind Library will expect these get passed as inputs to run_test() (or run_documentation_tests() instead).
Re-running the confusion matrix with normalize=True looks like this:
# Test dataset with normalize=True
result = vm.tests.run_test(
"my_custom_tests.ConfusionMatrix:test_dataset_normalized",
inputs={"model": vm_model, "dataset": vm_test_ds},
params={"normalize": True},
)As you saw in the pearson correlation example, you can log any result to the ValidMind Platform with the .log() method of the result object. This will allow you to add the result to the documentation.
You can now do the same for the confusion matrix results.
result.log()Creating inline custom tests with a function is a great way to customize your model documentation. However, sometimes you may want to reuse the same set of tests across multiple models and share them with developers in your organization. In this case, you can create a custom test provider that will allow you to load custom tests from a local folder or a git repository.
In this section you will learn how to declare a local filesystem test provider that allows loading tests from a local folder following these high level steps:
LocalTestProvider that points to that folderHere you will create a new folder that will contain reusable, custom tests. The following code snippet will create a new my_tests directory in the current working directory if it doesn’t exist.
tests_folder = "my_tests"
import os
# create tests folder
os.makedirs(tests_folder, exist_ok=True)
# remove existing tests
for f in os.listdir(tests_folder):
# remove files and pycache
if f.endswith(".py") or f == "__pycache__":
os.system(f"rm -rf {tests_folder}/{f}")After running the command above, you should see a new directory next to this notebook file:
The @vm.test decorator that was used above to register these as one-off custom tests also adds a convenience method to the function object that allows you to simply call <func_name>.save() to save it to a file. This will save the function to a Python file to a path you specify. In this case, you can pass the variable tests_folder to save it to the custom tests folder we created.
Normally, this will get you started by creating the file and saving the function code with the correct name. But it won’t automatically add any import or other functions/variables outside of the function that are needed for the test to run. The save() method allows you to pass an optional imports argument that will ensure the necessary imports are added to the file.
For the confusion_matrix test, note the imports that are required for the function to run properly:
import matplotlib.pyplot as plt
from sklearn import metricsYou can pass these imports to the save() method to ensure they are included in the file with the following command:
confusion_matrix.save(
tests_folder,
imports=["import matplotlib.pyplot as plt", "from sklearn import metrics"],
)2024-11-26 20:20:11,078 - INFO(validmind.tests.decorator): Saved to /home/runner/work/documentation/documentation/site/notebooks/tutorials/my_tests/ConfusionMatrix.py!Be sure to add any necessary imports to the top of the file.
2024-11-26 20:20:11,079 - INFO(validmind.tests.decorator): This metric can be run with the ID: <test_provider_namespace>.ConfusionMatrixThe save() method saved the confusion_matrix function to a file named ConfusionMatrix.py in the my_tests folder. Note that the new file provides some context on the origin of the test, which is useful for traceability.
# Saved from __main__.confusion_matrix
# Original Test ID: my_custom_tests.ConfusionMatrix
# New Test ID: <test_provider_namespace>.ConfusionMatrixAdditionally, the new test function has been stripped off its decorator, as it now resides in a file that will be loaded by the test provider:
def ConfusionMatrix(dataset, model, normalize=False):LocalTestProvider that points to that folderWith the my_tests folder now having a sample custom test, you can now initialize a test provider that will tell the ValidMind Library where to find these tests. ValidMind offers out-of-the-box test providers for local tests (i.e. tests in a folder) or a Github provider for tests in a Github repository. You can also create your own test provider by creating a class that has a load_test method that takes a test ID and returns the test function matching that ID.
The most important attribute for a test provider is its namespace. This is a string that will be used to prefix test IDs in model documentation. This allows you to have multiple test providers with tests that can even share the same ID, but are distinguished by their namespace.
An extended introduction to test providers can be found in this notebook.
For most use-cases, the local test provider should be sufficient. This test provider allows you load custom tests from a designated directory. Let’s go ahead and see how we can do this with our custom tests.
from validmind.tests import LocalTestProvider
# initialize the test provider with the tests folder we created earlier
my_test_provider = LocalTestProvider(tests_folder)
vm.tests.register_test_provider(
namespace="my_test_provider",
test_provider=my_test_provider,
)
# `my_test_provider.load_test()` will be called for any test ID that starts with `my_test_provider`
# e.g. `my_test_provider.ConfusionMatrix` will look for a function named `ConfusionMatrix` in `my_tests/ConfusionMatrix.py` fileNow that you have set up the test provider, you can run any test that’s located in the tests folder by using the run_test() method as with any other test. For tests that reside in a test provider directory, the test ID will be the namespace specified when registering the provider, followed by the path to the test file relative to the tests folder. For example, the Confusion Matrix test we created earlier will have the test ID my_test_provider.ConfusionMatrix. You could organize the tests in subfolders, say classification and regression, and the test ID for the Confusion Matrix test would then be my_test_provider.classification.ConfusionMatrix.
Let’s go ahead and re-run the confusion matrix test by using the test ID my_test_provider.ConfusionMatrix. This should load the test from the test provider and run it as before.
result = vm.tests.run_test(
"my_test_provider.ConfusionMatrix",
inputs={"model": vm_model, "dataset": vm_test_ds},
params={"normalize": True},
)
result.log()You have already seen how to add individual results to the model documentation using the ValidMind Platform. Let’s repeat the process and add the confusion matrix to the Model Development -> Model Evaluation section of the documentation. The “add test driven block” dialog should now show the new test result coming from the test provider:
In this section we cover how to finalize the testing and documentation of your model by focusing on:
run_documentation_tests() to ensure custom test results are included in your documentationrun_documentation_tests() to ensure custom test results are included in your documentationAfter adding test driven blocks to your model documentation, changes should persist and become available every time you call vm.preview_template(). However, you need to reload the connection to the ValidMind Platform if you have added test driven blocks when the connection was already established.
vm.reload()Now, run preview_template() and verify that the new confusion matrix test you added is included in the proper section.
vm.preview_template()Since the test ID is now registered in the document you can now run tests for an entire section and all additional custom tests should be loaded without issues. Let’s run all tests in the model_evaluation section of the documentation. Note that we have been running the sample custom confusion matrix with normalize=True to demonstrate the ability to provide custom parameters.
In the Run the model evaluation tests section above you learned how to assign inputs to individual tests with run_documentation_tests(). Assigning parametesr is similar, you only need to provide assign a params dictionary to a given test ID, my_test_provider.ConfusionMatrix in this case.
test_config = {
"validmind.model_validation.sklearn.ClassifierPerformance:in_sample": {
"inputs": {
"dataset": vm_train_ds,
"model": vm_model,
},
},
"my_test_provider.ConfusionMatrix": {
"params": {"normalize": True},
},
}
results = vm.run_documentation_tests(
section=["model_evaluation"],
inputs={
"dataset": vm_test_ds, # Any test that requires a single dataset will use vm_test_ds
"model": vm_model,
"datasets": (
vm_train_ds,
vm_test_ds,
), # Any test that requires multiple datasets will use vm_train_ds and vm_test_ds
},
config=test_config,
)2024-11-26 20:20:16,391 - WARNING(validmind.vm_models.test_suite.runner): Config key 'my_test_provider.ConfusionMatrix' does not match a test_id in the template.
Ensure you registered a content block with the correct content_id in the template
The configuration for this test will be ignored.The ValidMind Library provides a utility function called vm.get_test_suite().get_default_config() that allows you to render the default configuration for the entire documentation template. This configuration will contain all the test IDs and their default parameters. You can then modify this configuration as needed and pass it to run_documentation_tests() to run all tests in the documentation template if needed. You also have the option to continue running tests for one section at a time, get_default_config() still provides a useful reference for providing default parametes to every test.
import json
model_test_suite = vm.get_test_suite()
config = model_test_suite.get_default_config()
print("Suite Config: \n", json.dumps(config, indent=2))Suite Config:
{
"validmind.data_validation.DatasetDescription": {
"inputs": {
"dataset": null
},
"params": {}
},
"validmind.data_validation.ClassImbalance": {
"inputs": {
"dataset": null
},
"params": {
"min_percent_threshold": 10
}
},
"validmind.data_validation.Duplicates": {
"inputs": {
"dataset": null
},
"params": {
"min_threshold": 1
}
},
"validmind.data_validation.HighCardinality": {
"inputs": {
"dataset": null
},
"params": {
"num_threshold": 100,
"percent_threshold": 0.1,
"threshold_type": "percent"
}
},
"validmind.data_validation.MissingValues": {
"inputs": {
"dataset": null
},
"params": {
"min_threshold": 1
}
},
"validmind.data_validation.Skewness": {
"inputs": {
"dataset": null
},
"params": {
"max_threshold": 1
}
},
"validmind.data_validation.UniqueRows": {
"inputs": {
"dataset": null
},
"params": {
"min_percent_threshold": 1
}
},
"validmind.data_validation.TooManyZeroValues": {
"inputs": {
"dataset": null
},
"params": {
"max_percent_threshold": 0.03
}
},
"validmind.data_validation.IQROutliersTable": {
"inputs": {
"dataset": null
},
"params": {
"threshold": 1.5
}
},
"validmind.data_validation.IQROutliersBarPlot": {
"inputs": {
"dataset": null
},
"params": {
"threshold": 1.5,
"fig_width": 800
}
},
"validmind.data_validation.DescriptiveStatistics": {
"inputs": {
"dataset": null
},
"params": {}
},
"validmind.data_validation.PearsonCorrelationMatrix": {
"inputs": {
"dataset": null
},
"params": {}
},
"validmind.data_validation.HighPearsonCorrelation": {
"inputs": {
"dataset": null
},
"params": {
"max_threshold": 0.3
}
},
"validmind.model_validation.ModelMetadata": {
"inputs": {
"model": null
},
"params": {}
},
"validmind.data_validation.DatasetSplit": {
"inputs": {
"datasets": null
},
"params": {}
},
"validmind.model_validation.sklearn.PopulationStabilityIndex": {
"inputs": {
"model": null,
"datasets": null
},
"params": {
"num_bins": 10,
"mode": "fixed"
}
},
"validmind.model_validation.sklearn.ConfusionMatrix": {
"inputs": {
"model": null,
"dataset": null
},
"params": {}
},
"validmind.model_validation.sklearn.ClassifierPerformance:in_sample": {
"inputs": {
"model": null,
"dataset": null
},
"params": {
"average": "macro"
}
},
"validmind.model_validation.sklearn.ClassifierPerformance:out_of_sample": {
"inputs": {
"model": null,
"dataset": null
},
"params": {
"average": "macro"
}
},
"validmind.model_validation.sklearn.PrecisionRecallCurve": {
"inputs": {
"model": null,
"dataset": null
},
"params": {}
},
"validmind.model_validation.sklearn.ROCCurve": {
"inputs": {
"model": null,
"dataset": null
},
"params": {}
},
"validmind.model_validation.sklearn.TrainingTestDegradation": {
"inputs": {
"model": null,
"datasets": null
},
"params": {
"metrics": [
"accuracy",
"precision",
"recall",
"f1"
],
"max_threshold": 0.1
}
},
"validmind.model_validation.sklearn.MinimumAccuracy": {
"inputs": {
"model": null,
"dataset": null
},
"params": {
"min_threshold": 0.7
}
},
"validmind.model_validation.sklearn.MinimumF1Score": {
"inputs": {
"model": null,
"dataset": null
},
"params": {
"min_threshold": 0.5
}
},
"validmind.model_validation.sklearn.MinimumROCAUCScore": {
"inputs": {
"model": null,
"dataset": null
},
"params": {
"min_threshold": 0.5
}
},
"validmind.model_validation.sklearn.PermutationFeatureImportance": {
"inputs": {
"model": null,
"dataset": null
},
"params": {
"fontsize": null,
"figure_height": 1000
}
},
"validmind.model_validation.sklearn.SHAPGlobalImportance": {
"inputs": {
"model": null,
"dataset": null
},
"params": {
"kernel_explainer_samples": 10,
"tree_or_linear_explainer_samples": 200,
"class_of_interest": null
}
},
"validmind.model_validation.sklearn.WeakspotsDiagnosis": {
"inputs": {
"model": null,
"datasets": null
},
"params": {
"features_columns": null,
"thresholds": {
"accuracy": 0.75,
"precision": 0.5,
"recall": 0.5,
"f1": 0.7
}
}
},
"validmind.model_validation.sklearn.OverfitDiagnosis": {
"inputs": {
"model": null,
"datasets": null
},
"params": {
"metric": null,
"cut_off_threshold": 0.04
}
},
"validmind.model_validation.sklearn.RobustnessDiagnosis": {
"inputs": {
"model": null,
"datasets": null
},
"params": {
"metric": null,
"scaling_factor_std_dev_list": [
0.1,
0.2,
0.3,
0.4,
0.5
],
"performance_decay_threshold": 0.05
}
}
}Note that the default config does not assign any inputs to a test, this is expected. You can assign inputs to individual tests as needed, depending on the datasets and models you want to pass to individual tests. The config dictionary, as a mapping of test IDs to test configurations, allows you to do this.
For this particular documentation template (binary classification), the ValidMind Library provides a sample configuration that can be used to populate the entire model documentation using the following inputs as placeholders:
raw_dataset raw datasettrain_dataset training datasettest_dataset test datasetmodel instanceAs part of updating the config you will need to ensure the correct input_ids are used in the final config passed to run_documentation_tests().
from validmind.datasets.classification import customer_churn
from validmind.utils import preview_test_config
test_config = customer_churn.get_demo_test_config()
preview_test_config(test_config)Using this sample configuration, let’s finish populating model documentation by running all tests for the model_development section of the documentation. Recall that the training and test datasets in our exercise have the following input_id values:
train_dataset_final for the training datasettest_dataset_final for the test datasetconfig = {
"validmind.model_validation.ModelMetadata": {
"inputs": {"model": "log_reg_model_v1"},
},
"validmind.data_validation.DatasetSplit": {
"inputs": {"datasets": ["train_dataset_final", "test_dataset_final"]},
},
"validmind.model_validation.sklearn.PopulationStabilityIndex": {
"inputs": {
"model": "log_reg_model_v1",
"datasets": ["train_dataset_final", "test_dataset_final"],
},
"params": {"num_bins": 10, "mode": "fixed"},
},
"validmind.model_validation.sklearn.ConfusionMatrix": {
"inputs": {"model": "log_reg_model_v1", "dataset": "test_dataset_final"},
},
"my_test_provider.ConfusionMatrix": {
"inputs": {"dataset": "test_dataset_final", "model": "log_reg_model_v1"},
},
"validmind.model_validation.sklearn.ClassifierPerformance:in_sample": {
"inputs": {"model": "log_reg_model_v1", "dataset": "train_dataset_final"}
},
"validmind.model_validation.sklearn.ClassifierPerformance:out_of_sample": {
"inputs": {"model": "log_reg_model_v1", "dataset": "test_dataset_final"}
},
"validmind.model_validation.sklearn.PrecisionRecallCurve": {
"inputs": {"model": "log_reg_model_v1", "dataset": "test_dataset_final"},
},
"validmind.model_validation.sklearn.ROCCurve": {
"inputs": {"model": "log_reg_model_v1", "dataset": "test_dataset_final"},
},
"validmind.model_validation.sklearn.TrainingTestDegradation": {
"inputs": {
"model": "log_reg_model_v1",
"datasets": ["train_dataset_final", "test_dataset_final"],
},
"params": {
"metrics": ["accuracy", "precision", "recall", "f1"],
"max_threshold": 0.1,
},
},
"validmind.model_validation.sklearn.MinimumAccuracy": {
"inputs": {"model": "log_reg_model_v1", "dataset": "test_dataset_final"},
"params": {"min_threshold": 0.7},
},
"validmind.model_validation.sklearn.MinimumF1Score": {
"inputs": {"model": "log_reg_model_v1", "dataset": "test_dataset_final"},
"params": {"min_threshold": 0.5},
},
"validmind.model_validation.sklearn.MinimumROCAUCScore": {
"inputs": {"model": "log_reg_model_v1", "dataset": "test_dataset_final"},
"params": {"min_threshold": 0.5},
},
"validmind.model_validation.sklearn.PermutationFeatureImportance": {
"inputs": {"model": "log_reg_model_v1", "dataset": "test_dataset_final"},
},
"validmind.model_validation.sklearn.SHAPGlobalImportance": {
"inputs": {"model": "log_reg_model_v1", "dataset": "test_dataset_final"},
"params": {"kernel_explainer_samples": 10},
},
"validmind.model_validation.sklearn.WeakspotsDiagnosis": {
"inputs": {
"model": "log_reg_model_v1",
"datasets": ["train_dataset_final", "test_dataset_final"],
},
"params": {
"thresholds": {"accuracy": 0.75, "precision": 0.5, "recall": 0.5, "f1": 0.7}
},
},
"validmind.model_validation.sklearn.OverfitDiagnosis": {
"inputs": {
"model": "log_reg_model_v1",
"datasets": ["train_dataset_final", "test_dataset_final"],
},
"params": {"cut_off_percentage": 4},
},
"validmind.model_validation.sklearn.RobustnessDiagnosis": {
"inputs": {
"model": "log_reg_model_v1",
"datasets": ["train_dataset_final", "test_dataset_final"],
},
"params": {
"scaling_factor_std_dev_list": [0.0, 0.1, 0.2, 0.3, 0.4, 0.5],
"accuracy_decay_threshold": 4,
},
},
}
full_suite = vm.run_documentation_tests(
section="model_development",
config=config,
)2024-11-26 20:20:26,848 - WARNING(validmind.vm_models.test_suite.runner): Config key 'my_test_provider.ConfusionMatrix' does not match a test_id in the template.
Ensure you registered a content block with the correct content_id in the template
The configuration for this test will be ignored.2024-11-26 20:20:27,325 - ERROR(validmind.vm_models.test_suite.test): Failed to run test 'validmind.model_validation.sklearn.SHAPGlobalImportance': (TypeError) loop of ufunc does not support argument 0 of type float which has no callable rint method
2024-11-26 20:20:31,737 - INFO(validmind.tests.model_validation.sklearn.OverfitDiagnosis): Using default classification metric: auc
2024-11-26 20:20:31,738 - INFO(validmind.tests.model_validation.sklearn.OverfitDiagnosis): Using default cut-off threshold of 0.04
2024-11-26 20:20:32,619 - INFO(validmind.tests.model_validation.sklearn.RobustnessDiagnosis): Using default metric (AUC) for robustness diagnosis
2024-11-26 20:20:32,621 - INFO(validmind.tests.model_validation.sklearn.RobustnessDiagnosis): Using default performance decay threshold of 0.05In this notebook you have learned the end-to-end process to document a model with the ValidMind Library, running through some very common scenarios in a typical model development setting:
As a next step, you can explore the following notebooks to get a deeper understanding on how the ValidMind Library allows you generate model documentation for any use case:
All notebook samples can be found in the following directories of the ValidMind Library GitHub repository:
Retrieve the information for the currently installed version of ValidMind:
%pip show validmindUsing fork() can cause Polars to deadlock in the child process.
In addition, using fork() with Python in general is a recipe for mysterious
deadlocks and crashes.
The most likely reason you are seeing this error is because you are using the
multiprocessing module on Linux, which uses fork() by default. This will be
fixed in Python 3.14. Until then, you want to use the "spawn" context instead.
See https://docs.pola.rs/user-guide/misc/multiprocessing/ for details.
Name: validmind
Version: 2.5.25
Summary: ValidMind Library
Home-page:
Author: Andres Rodriguez
Author-email: andres@validmind.ai
License: Commercial License
Location: /home/runner/.local/lib/python3.10/site-packages
Requires: aiohttp, arch, bert-score, catboost, datasets, evaluate, ipywidgets, kaleido, langdetect, latex2mathml, llvmlite, matplotlib, mistune, nest-asyncio, nltk, numba, numpy, openai, pandas, plotly, plotly-express, polars, python-dotenv, rouge, scikit-learn, scipy, scorecardpy, seaborn, sentry-sdk, shap, statsmodels, tabulate, textblob, tqdm, xgboost, ydata-profiling
Required-by:
Note: you may need to restart the kernel to use updated packages.If the version returned is lower than the version indicated in our production open-source code, restart your notebook and run:
%pip install --upgrade validmindYou may need to restart your kernel after running the upgrade package for changes to be applied.