May 22, 2024
Release highlights
Introductory notebook for model developers
Our new end-to-end notebook gives you a full introduction to the ValidMind Developer Framework. You can use this notebook to learn how the end-to-end documentation process works, based on common scenarios you encounter in model development settings.
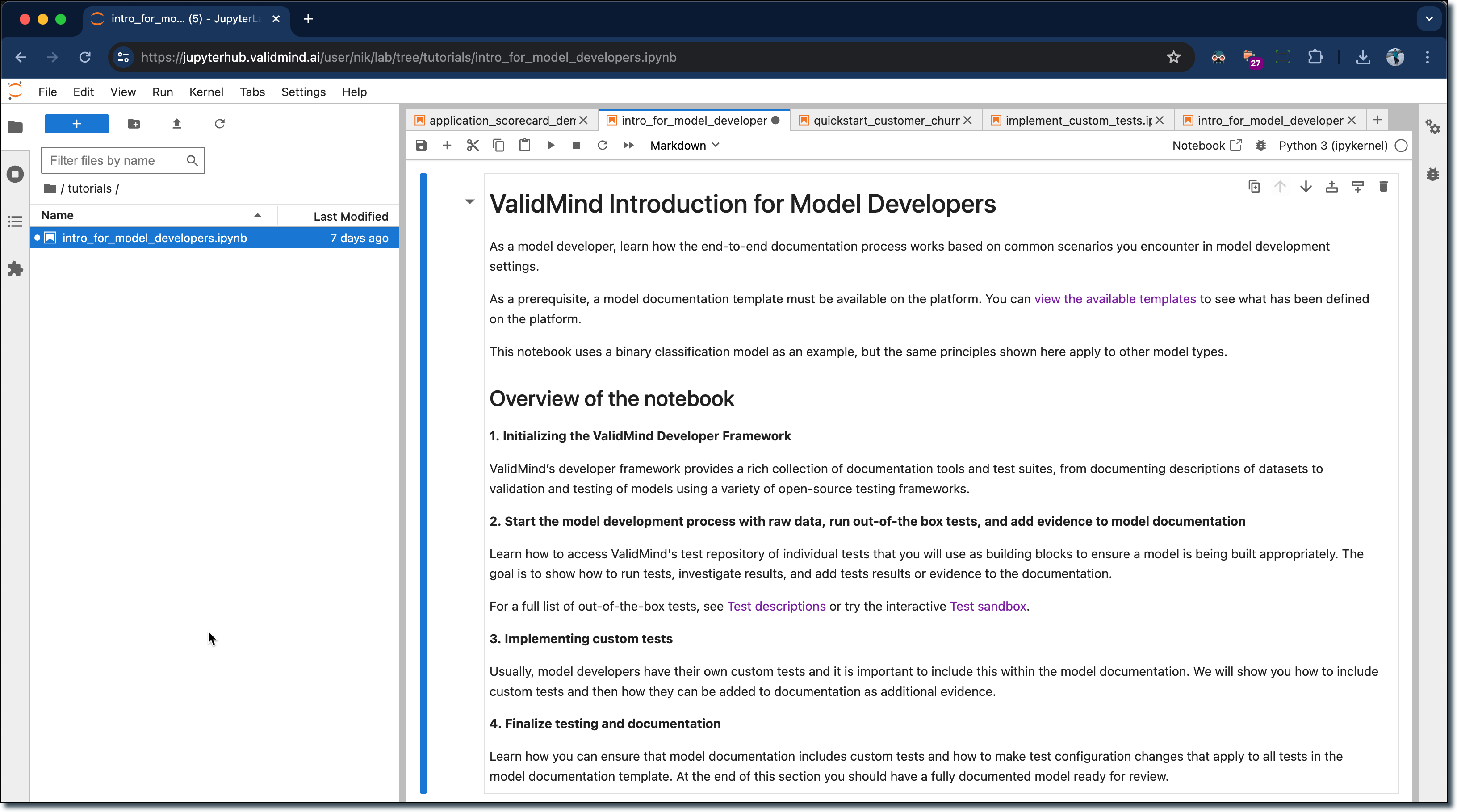
High level sections include:
Initializing the ValidMind Developer Framework — The developer framework provides tools for documentation and testing, from dataset descriptions to model validation using various open-source frameworks.
Starting the model development process — Access the test repository to use individual tests as building blocks for model development. Learn to run tests, analyze results, and add evidence to model documentation.
See the full list of tests at Test descriptions or try the Test sandbox.
Implementing custom tests — Include custom tests in model documentation. Learn how to add these tests and use them as additional evidence.
Finalizing testing and documentation — Ensure model documentation includes custom tests and configure settings for all tests in the template. By the end, you should have a fully documented model ready for review.
Support for external models
You can now run documentation tests without passing a Python-native model object. This change enables you to document:
- Models that are developed in non-Python environments
- Non-standard model interfaces:
- Models deployed as APIs, such as SageMaker model endpoints
- Tools such as Spark where a model is not a typical object that exposes a
predict()interface
To run tests for these models, you typically must load model predictions from a file, dataset, and so on. The new init_model interface does not enforce a Python model object anymore. You only need to pass attributes that describe the model which is required as a best practice for model documentation.
Initializing an external model
Since there is no native Python object to pass to init_model, you instead pass attributes that describe the model:
# Assume you want to load predictions for a PySpark ML model
model_attributes = {
"architecture": "Spark",
"language": "PySpark",
}
# Or maybe you're loading predictions for a SageMaker endpoint (model API)
model_attributes = {
"architecture": "SageMaker Model",
"language": "Python",
}
# Call `init_model` without passing a model. Pass `attributes` instead.
vm_model = vm.init_model(
attributes=model_attributes,
input_id="model",
)Assigning predictions
Since there’s no model object available, the developer framework won’t be able to call model.predict() or model.predict_proba(). You need to load predictions and probabilities manually. For example:
vm_train_ds.assign_predictions(
model=vm_model,
prediction_values=prediction_values,
prediction_probabilities=prediction_probabilities,
)You can proceed to run tests on your data as you would under normal conditions, without needing to modify any other parts of your code.
Custom test function decorators
We introduced a new metric decorator that turns any function into a ValidMind Test that you can use in your documentation. To learn what this decorator can do for you, try our code sample on JupyterHub!
Custom tests offer added flexibility. They allow you to extend the library of default tests provided by ValidMind which enables you to document any type of model or use case.
This new decorator simplifies creating and using custom tests by almost completely eliminating the boilerplate code required to define and register a custom test.
Documentation overview page
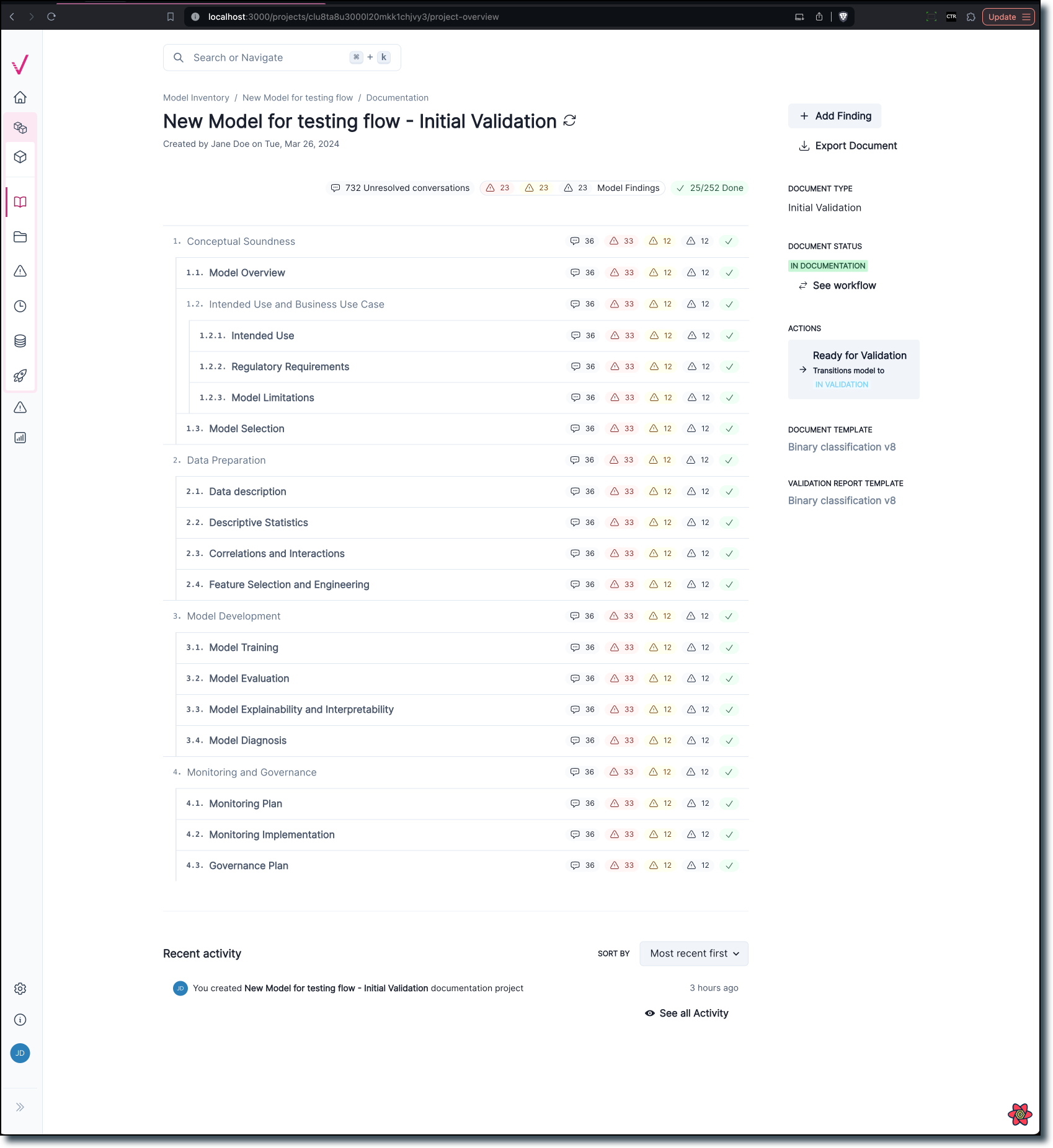
Our new documentation is designed to help you find the information you need more quickly.
Now more distinct from the Model Details page, the new overview page provides easier navigation and enhanced data visualization to better understand the progress of the documentation stage.
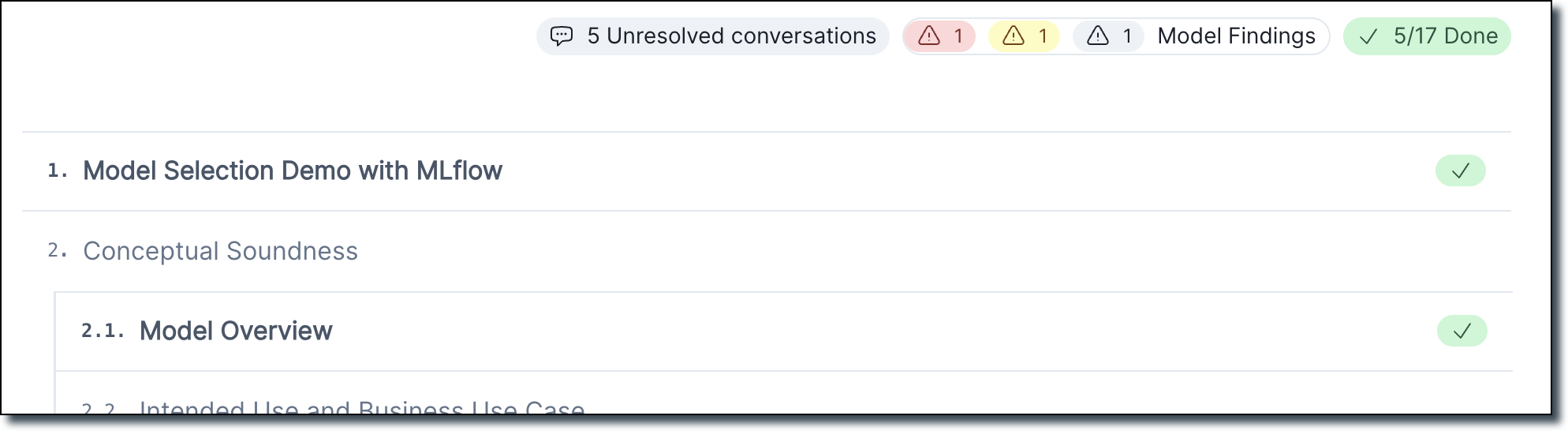
Documentation outline page with conversations
We created a new documentation outline page which replaces the existing project overview page. This page shows a section-by-section outline of your project’s documentation:
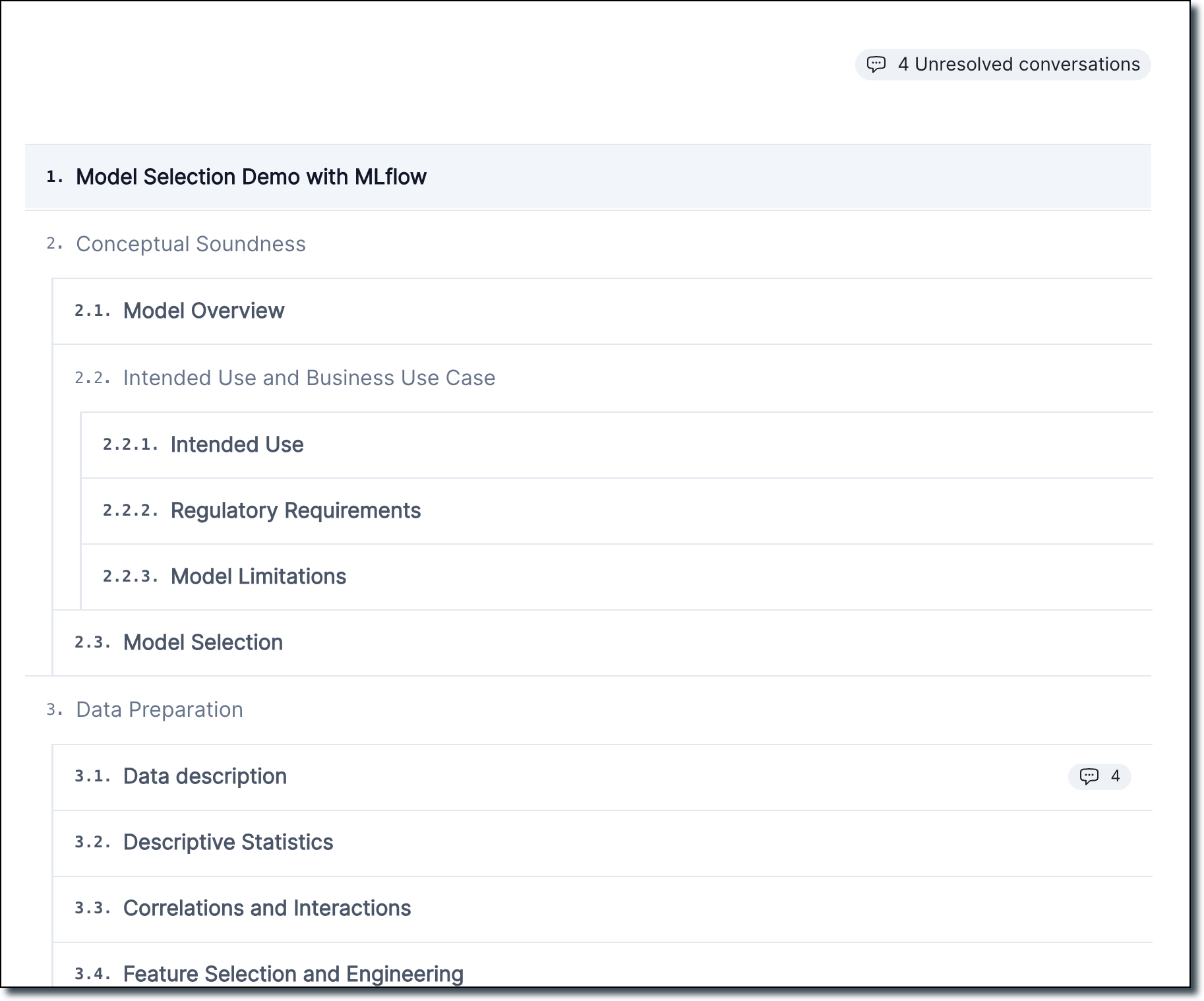
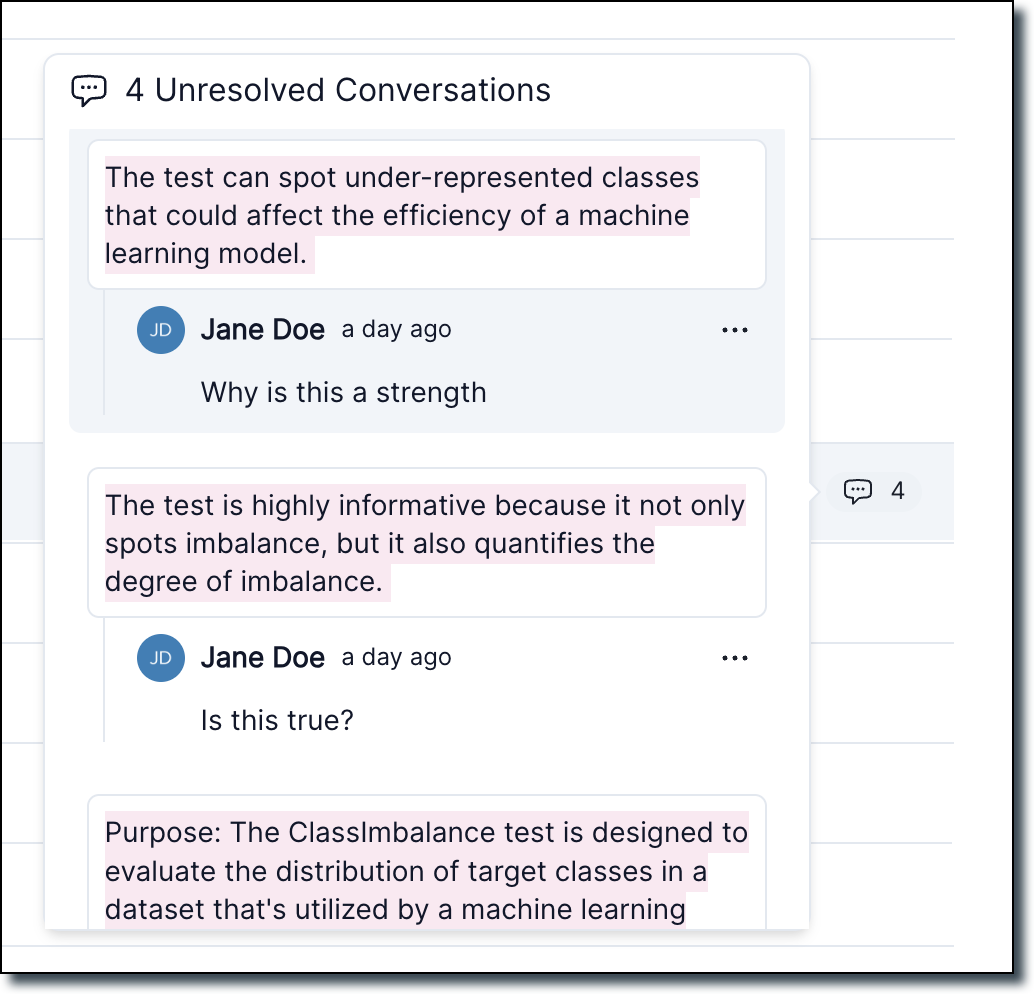
It also includes a count of every unresolved conversation within each section.
- From here, you can hover over the chat icon to see a preview of all unresolved conversations.
- Click a chat icon to jump to a conversations, or resolve conversations directly from the popup.
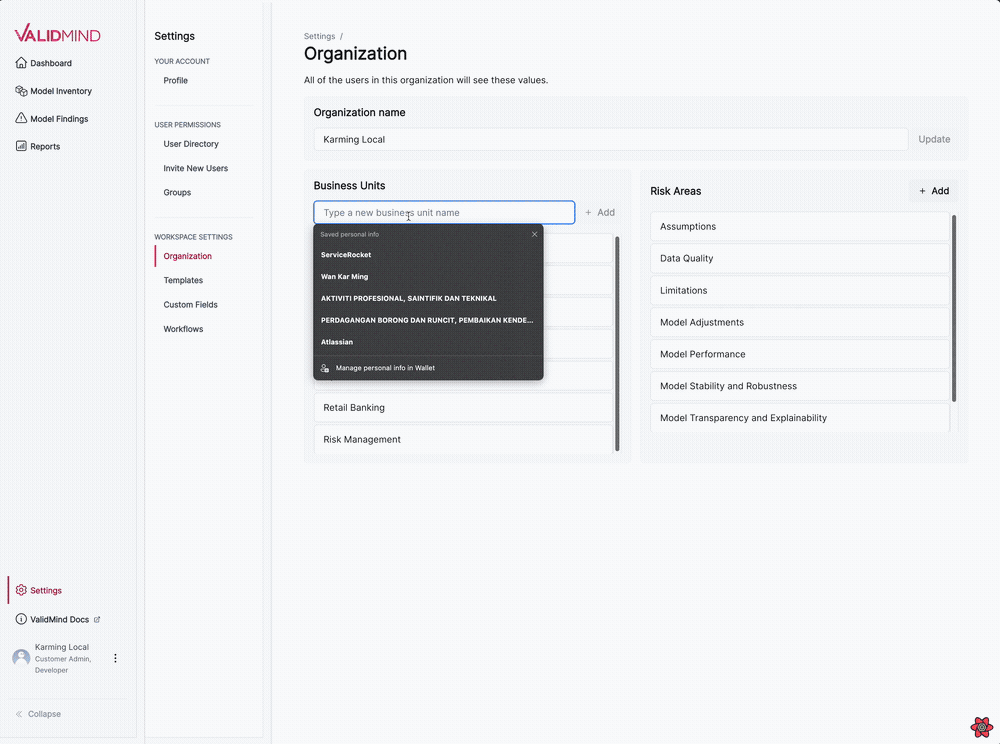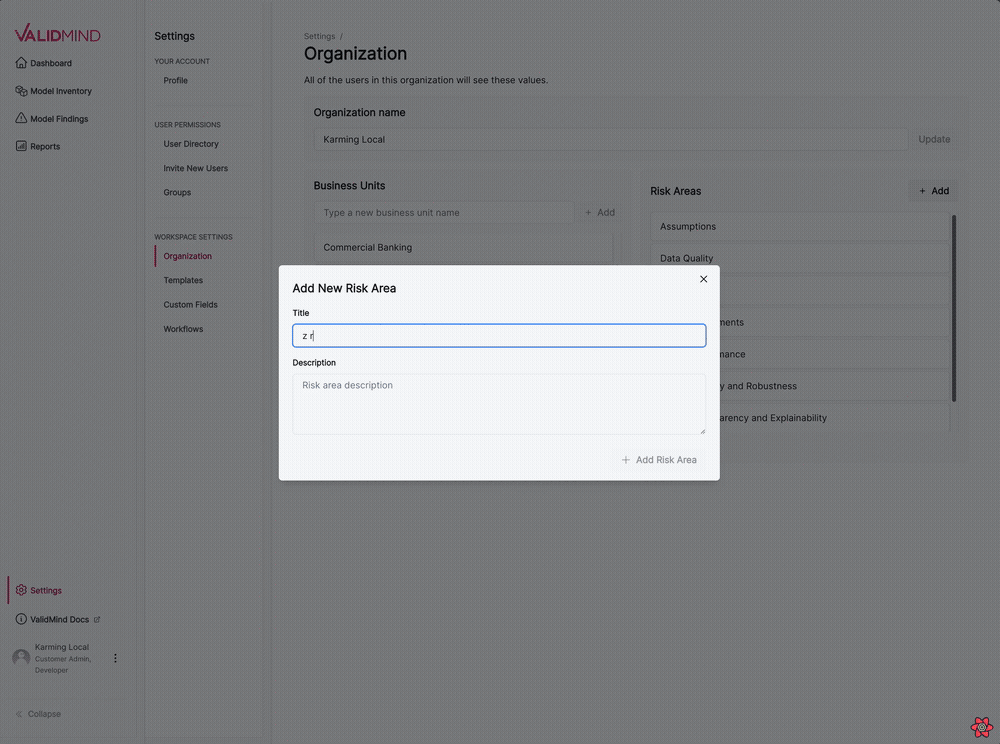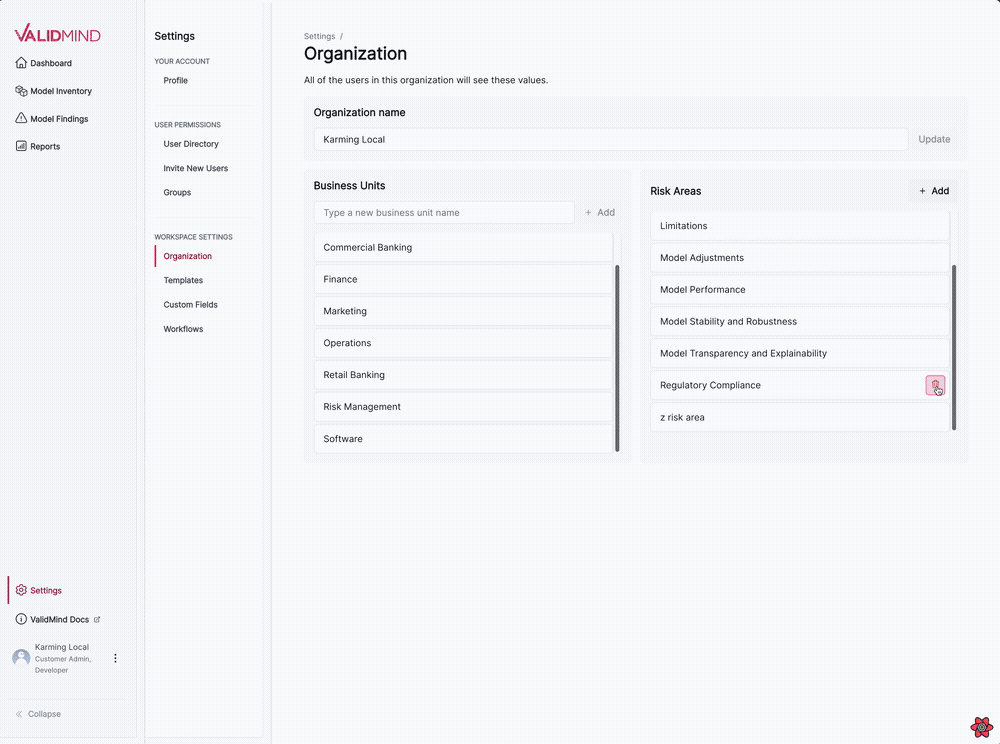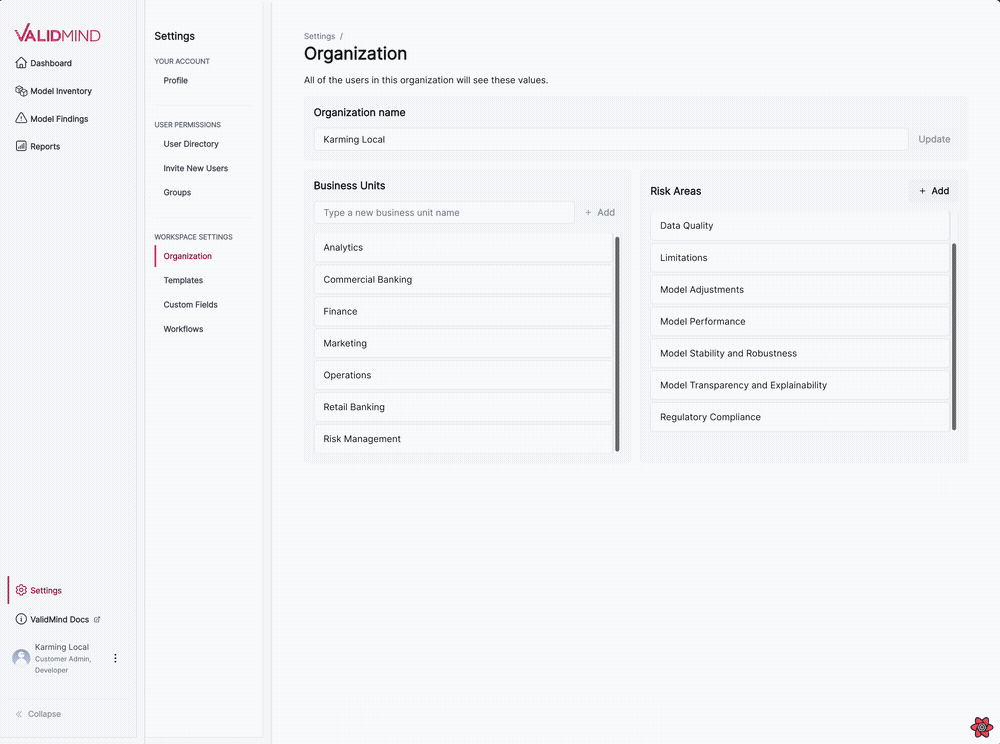
Business unit and risk areas settings for organizations
We have introduced several updates to the Organization settings page, enabling you to manage business units and risk areas for your organization.
The following features are now available:
- Add or remove business units from your organization.
- Remove business units from the organization settings page.
- Remove risk areas from the organization settings page.
- Add or remove risk areas from your organization.
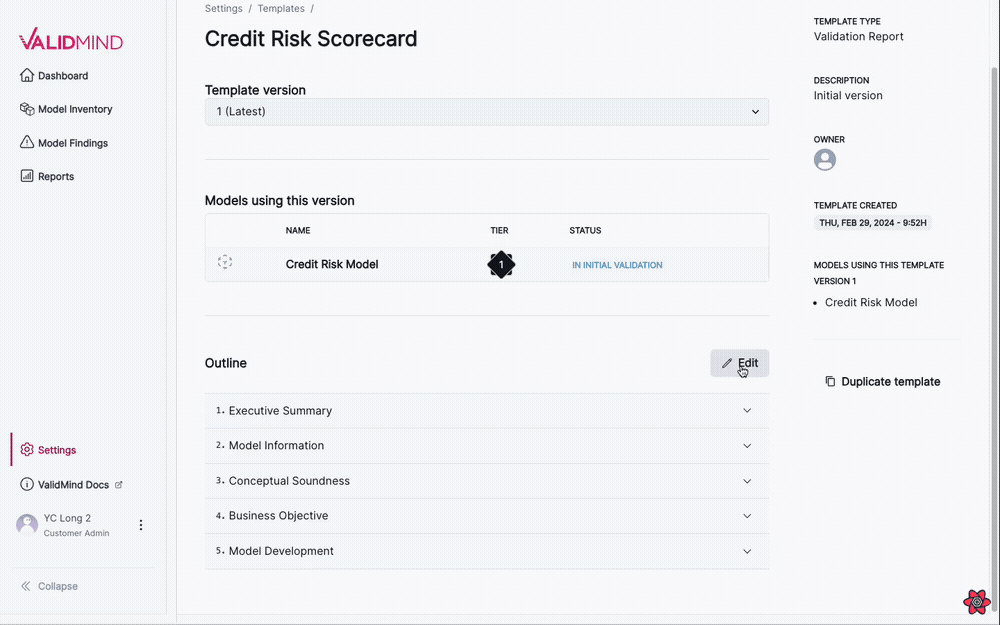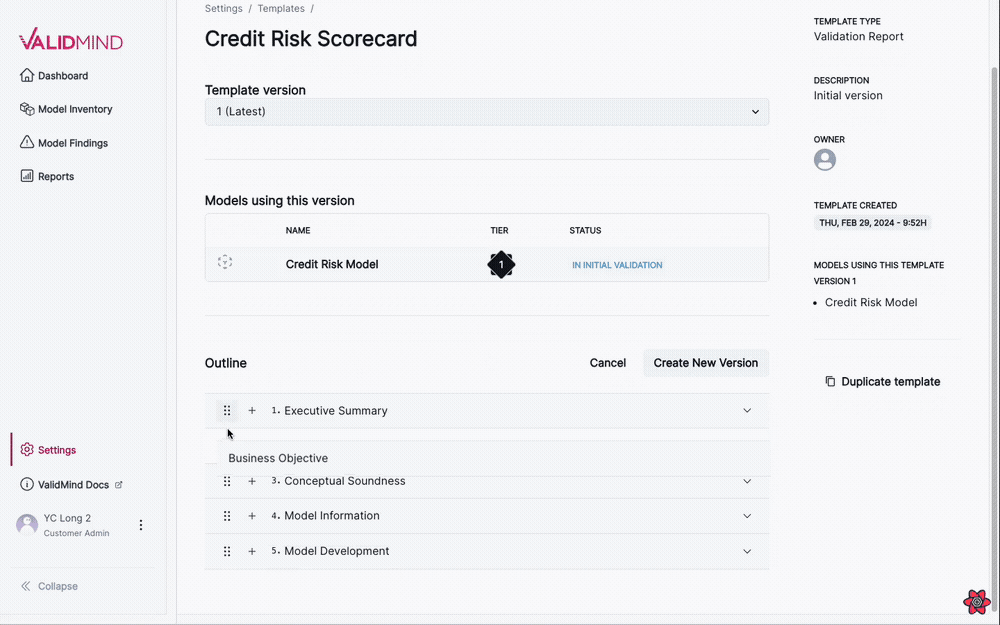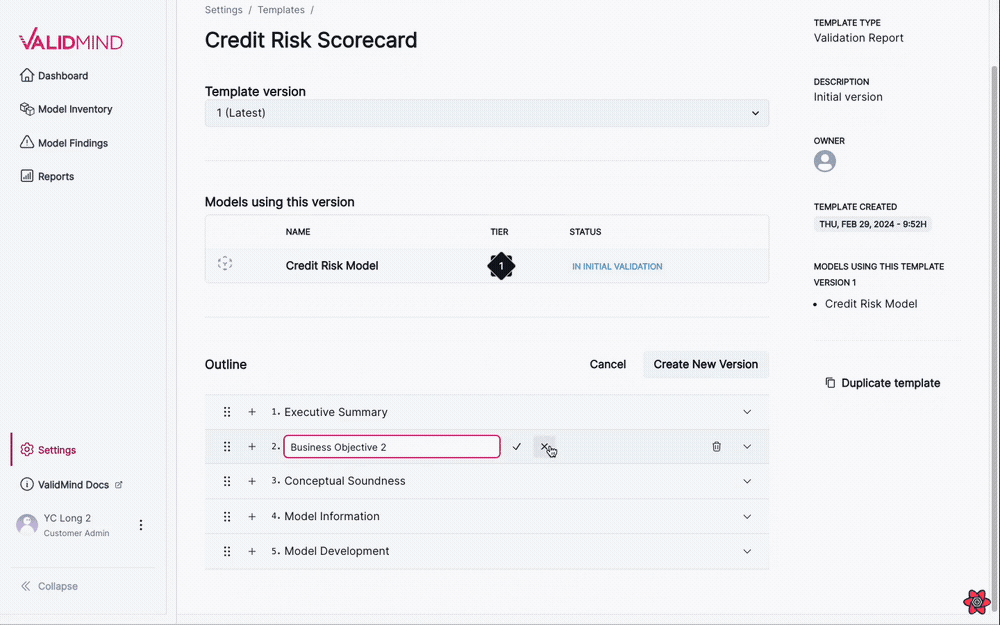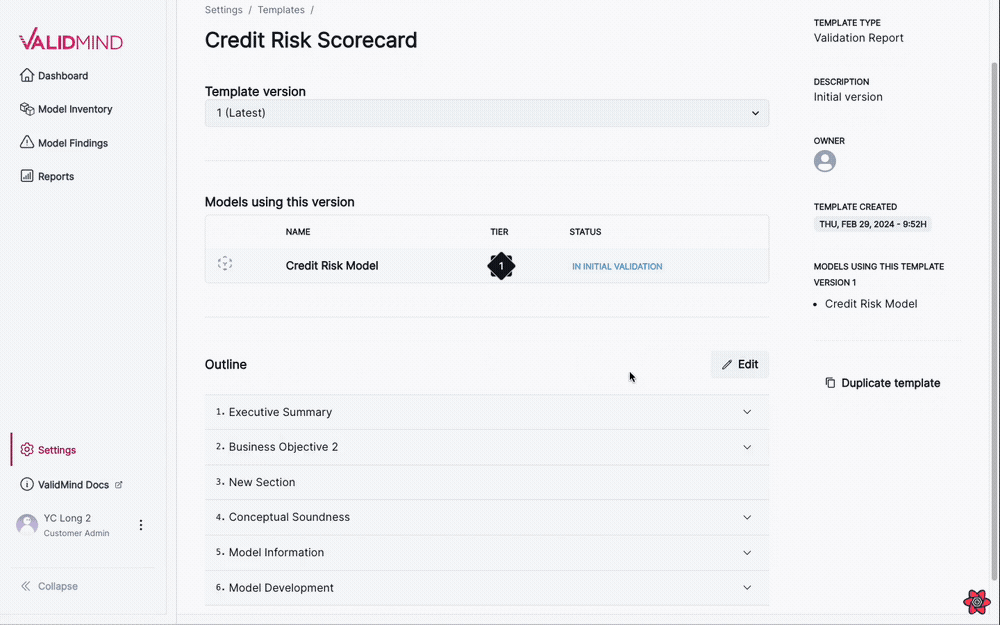
New documentation template editor
This update allows you to edit documentation templates visually, eliminating the need to manually edit YAML files. Add, remove, and rename sections with the new editor.
Enhanced template setting page
- The edit button next to the version dropdown is now hidden.
- A new edit button is displayed above the accordions. Clicking this button activates the edit mode for the accordion.
Edit mode functionality
- In edit mode, you see a cancel button to exit edit mode and a button to publish a new version of the template with the current changes.
- You can edit section titles when the accordion is in edit mode.
- You can insert new sections before or after an existing section or insert a sub-section.
- You can remove sections, with a confirmation alert to ensure the action.
This new visual editing interface streamlines the template editing process, making it more intuitive and user-friendly:
Enhancements
Add extra columns on the fly
We added support for two new VMDataset methods:
add_extra_column()get_extra_column()
add_extra_column()
You can now register arbitrary extra columns in a dataset when a test needs to compute metrics outside of the existing sets of columns (features, targets, predictions).
For example, credit risk-related metrics may require access to a list of scores computed from predictions. In this case, an extra column called scores is needed for computing the metrics.
Example usage:
# Init your dataset as usual
vm_train_ds = vm.init_dataset(
dataset=train_df,
input_id="train_dataset",
target_column=customer_churn.target_column,
)
# Generate scores using a user defined function:
scores = compute_my_scores(x_train)
# Assign a new "scores" column to vm_train_ds:
vm_train_ds.add_extra_column("scores", scores)This function returns an error if no column values are passed:
vm_train_ds.add_extra_column("scores")
ValueError: Column values must be provided when the column doesn't exist in the datasetIt’s also possible to use init_dataset with a dataset that has precomputed scores, for example:
> train_df.columns
Index(['CreditScore', 'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts',
'HasCrCard', 'IsActiveMember', 'EstimatedSalary', 'Exited',
'Geography_France', 'Geography_Germany', 'Geography_Spain'],
dtype='object')> train_df["my_scores"] = scores
> train_df.columns
Index(['CreditScore', 'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts',
'HasCrCard', 'IsActiveMember', 'EstimatedSalary', 'Exited',
'Geography_France', 'Geography_Germany', 'Geography_Spain',
'my_scores'],
dtype='object')Make sure you set the feature_columns correctly:
vm_train_ds = vm.init_dataset(
dataset=train_df,
input_id="another_ds",
feature_columns=[
"CreditScore",
"Gender",
"Age",
"Tenure",
"Balance",
"NumOfProducts",
"HasCrCard",
"IsActiveMember",
"EstimatedSalary",
"Exited",
"Geography_France",
"Geography_Germany",
"Geography_Spain",
],
target_column=customer_churn.target_column,
)Then, call add_extra_column() to register the extra column:
> another_ds.add_extra_column(column_name="my_scores")
Column my_scores exists in the dataset, registering as an extra columnget_extra_column()
You can use this inside a test to retrieve the extra column values.
Example usage:
scores = self.inputs.dataset.get_extra_column("scores")Create composite tests by combining multiple individual unit tests
ValidMind now supports the ability to compose multiple Unit Tests into complex outputs.
These composite tests can be logged as a single result that can be used as a content block in your documentation. The results from composite tests automatically update whenever you re-run the documentation test suite.
New text data validation tests
The following tests for text data validation have been added:
validmind.data_validation.nlp.LanguageDetectionvalidmind.data_validation.nlp.Toxicityvalidmind.data_validation.nlp.PolarityAndSubjectivityvalidmind.data_validation.nlp.Sentiment
Use test decorators with test providers
Continuing our efforts to simplify the process for getting your custom code working in ValidMind, we now support functional tests for internal tests and test providers. Functional tests are tests that can be defined as pure functions without any boilerplate.
Support for metadata in new metric decorator
We added new decorators to support task type and tag metadata in functional metrics.
Usage example:
from sklearn.metrics import accuracy_score
from validmind import tags, tasks
@tasks("classification")
@tags("classification", "sklearn", "accuracy")
def Accuracy(dataset, model):
"""Calculates the accuracy of a model"""
return accuracy_score(dataset.y, dataset.y_pred(model))
# the above decorator is syntactic sugar for the following:
Accuracy.__tags__ = ["classification"]
Accuracy.__tasks__ = ["classification", "sklearn", "accuracy"]Assign prediction probabilities
We added support for assigning prediction_probabilities to assign_predictions. This support enables you to:
- Assign prediction values and probabilities that have been computed outside ValidMind.
- Incorporate prediction values and probabilities from datasets that already have prediction columns.
- Automate the assignment of prediction values and probabilities within VM.
Associate findings with a documentation section
You can now associate Model Findings with sections within your model documentation. Doing so will allow you to track findings by severity, section-by-section, in the Documentation overview page.
You can see the total number of findings at the top of the Documentation overview page, as well as the individual counts per section. To view the related findings, hover over the finding icon in each section and click on one to jump to it.
Better UI for workflow customization
Our revamped workflows UI pages enable more granular management of model and documentation lifecycles and deep integration with model inventory attributes.
The new workflows UI includes the following features:
- Ability to require a user action (approve, reject, request changes, etc.) before updating the status of a resource. The user action is presented to relevant users as an action button.
- Ability to define the conditions that need to be met before allowing state transitions on a workflow. These conditions are evaluated from attribute values of the inventory model.
- Support for approval steps. Approval steps allow you to define the model attribute where a list of approvers needs retrieval and specify the percentage of approvals needed for a successful approval.
- Approval steps allow defining approved and rejected outcomes.
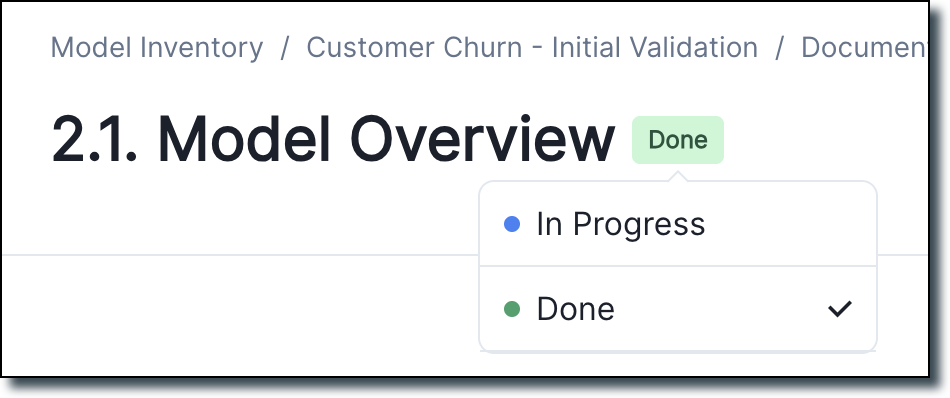
Set section status for model documentation and overview page
We added a status picker to each section of the model documentation page.
This picker allows you to set whether the section is In Progress or Done. The Documentation overview page displays a total count of how many sections have been completed, as well as a checkmark indicating that the section is done.
Specify a template for rich text inventory fields
We added a new property to the Long Text inventory field: ENABLE RICH TEXT FORMATTING.
- Toggling this property changes the field to a rich text editor rather than a simple text area.
- Another field called Template is also available and enables you to specify the default value within the rich text editor. This feature can be useful for defining procedures or guidelines that all models need to follow.
Validation report overview page
We created a new Validation Report overview page which shows a section-by-section outline of a model’s validation report, including a total compliance summary for all risk areas associated with the model.
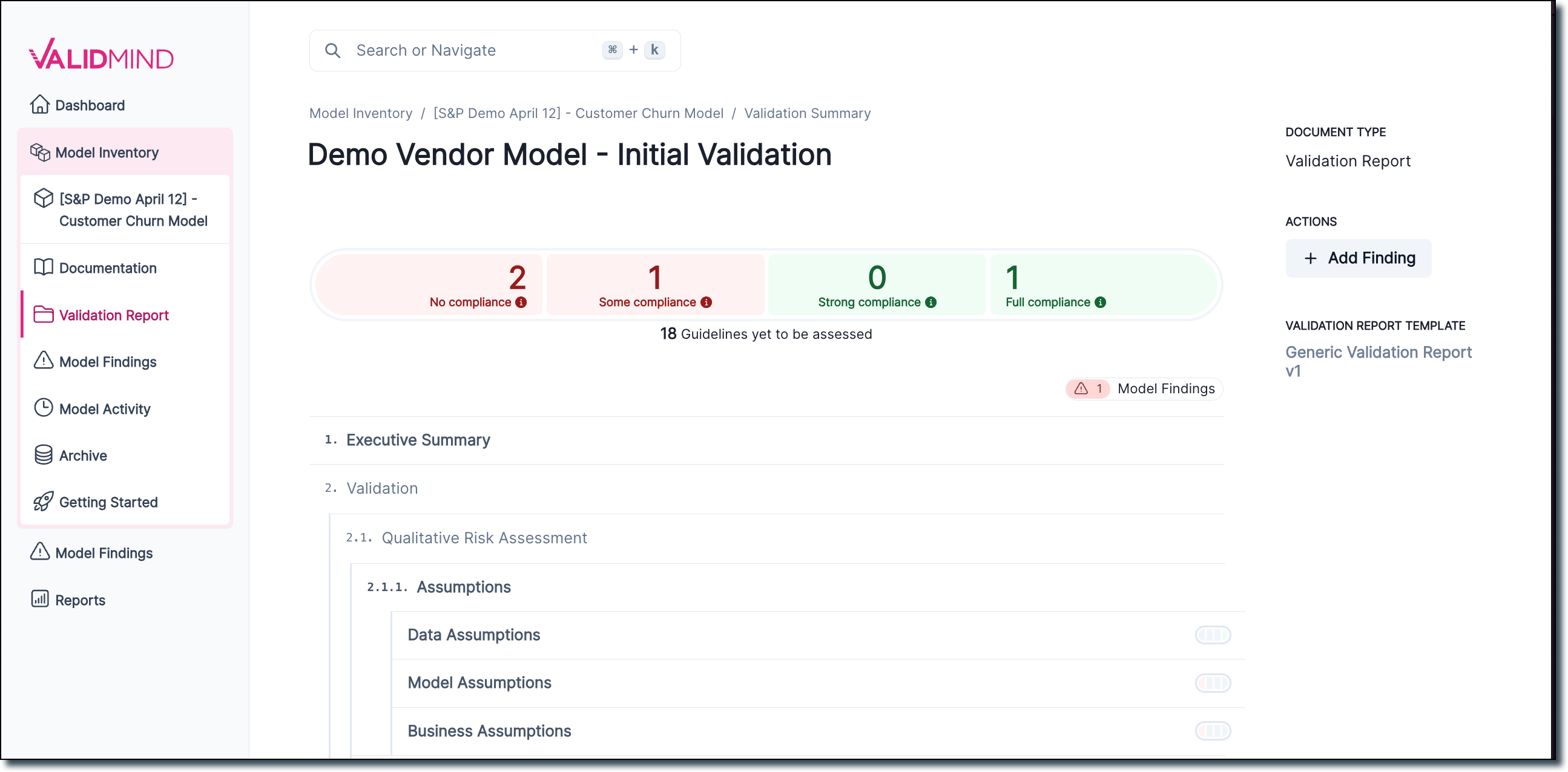
You can hover over any section in the report outline to view the current compliance status in the document section. The new validation report page also adds an Add finding button.
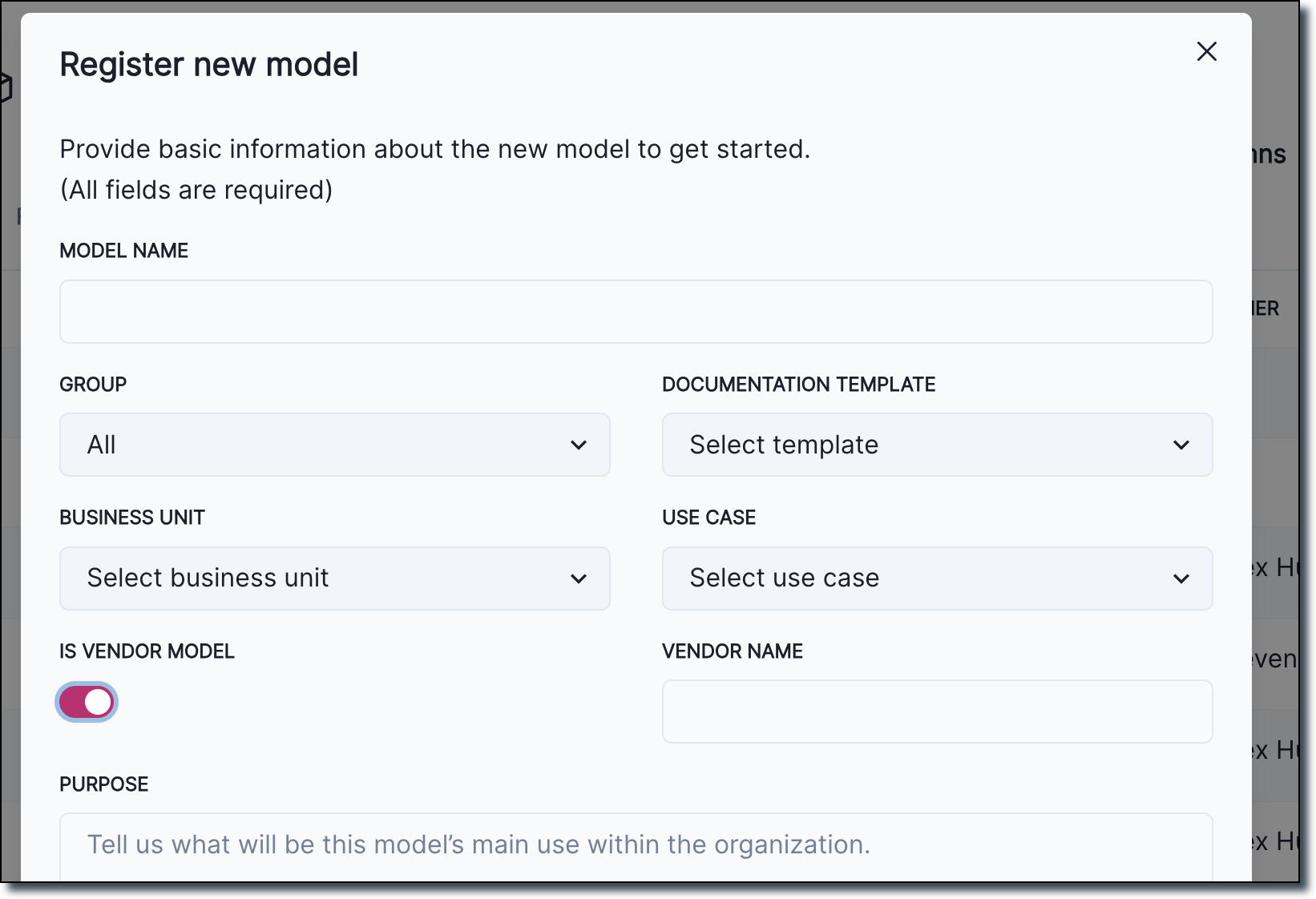
Specify vendor info during inventory registration and improved inventory model filters
We added the ability to flag models as Is Vendor Model and specify a vendor name.
How you add Vendor Model as a filtering flag:
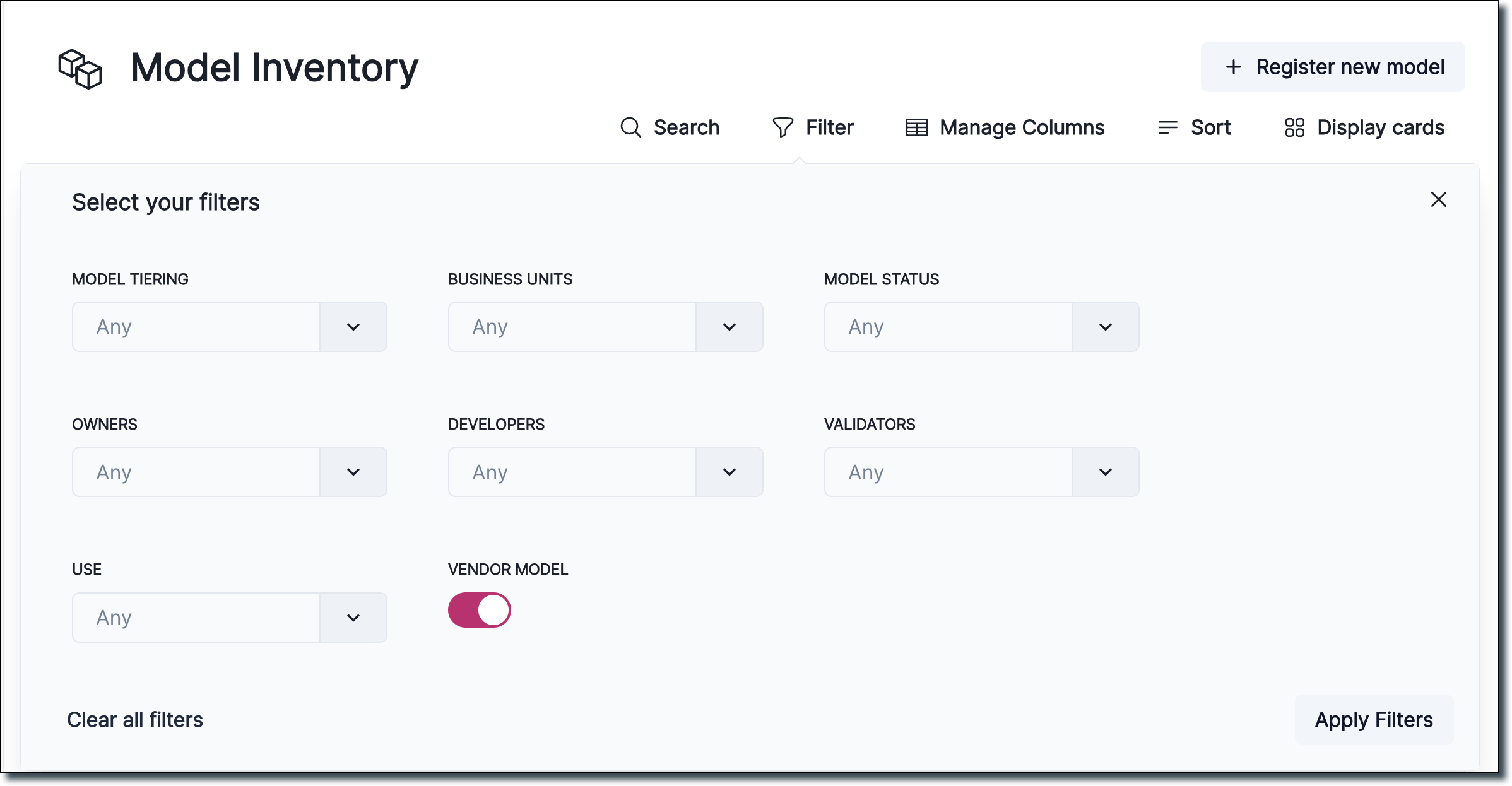
Also available is an improved look and functionality for model inventory filtering:
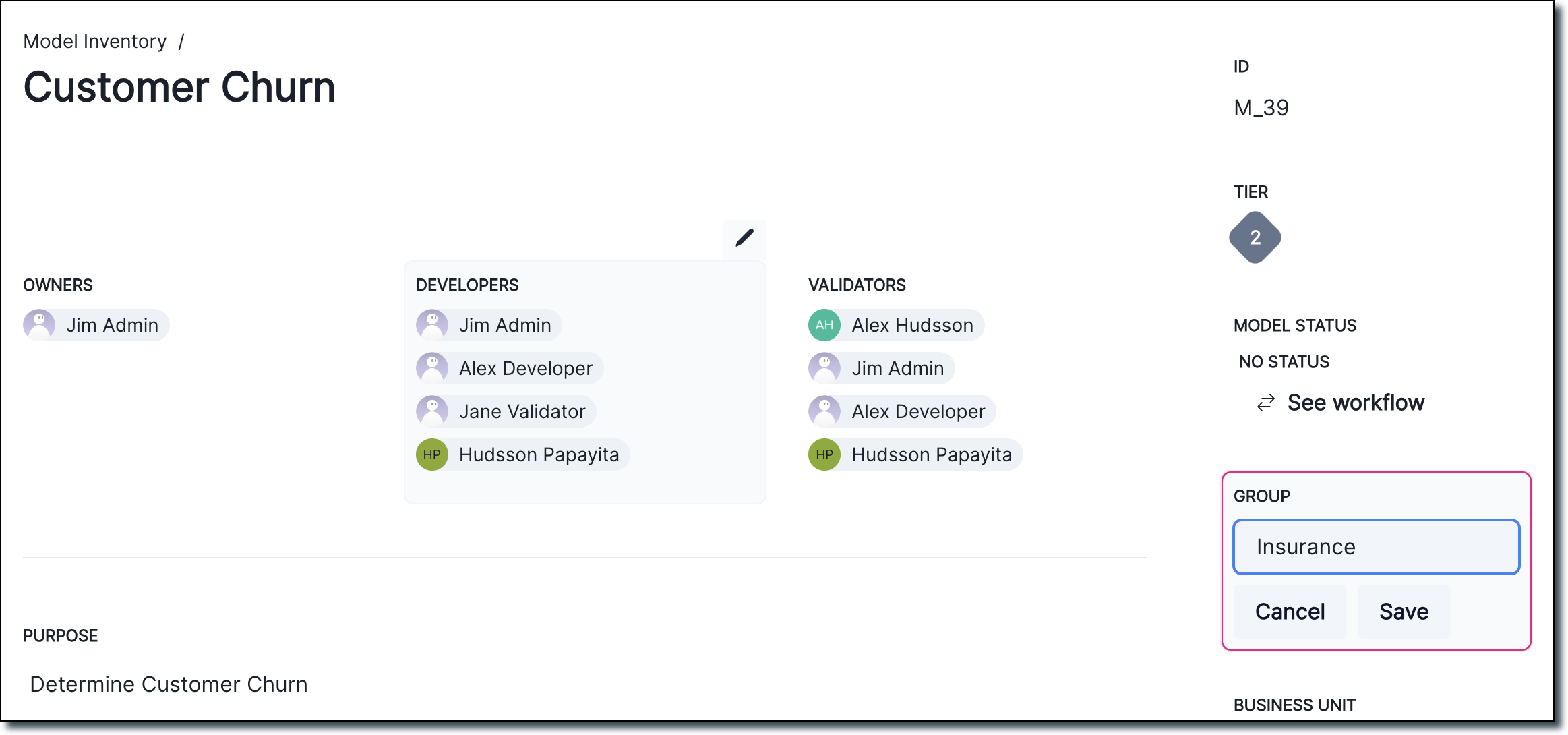
Display group information for inventory models
Admin users can now modify the group the inventory model belongs to:
Bug fixes
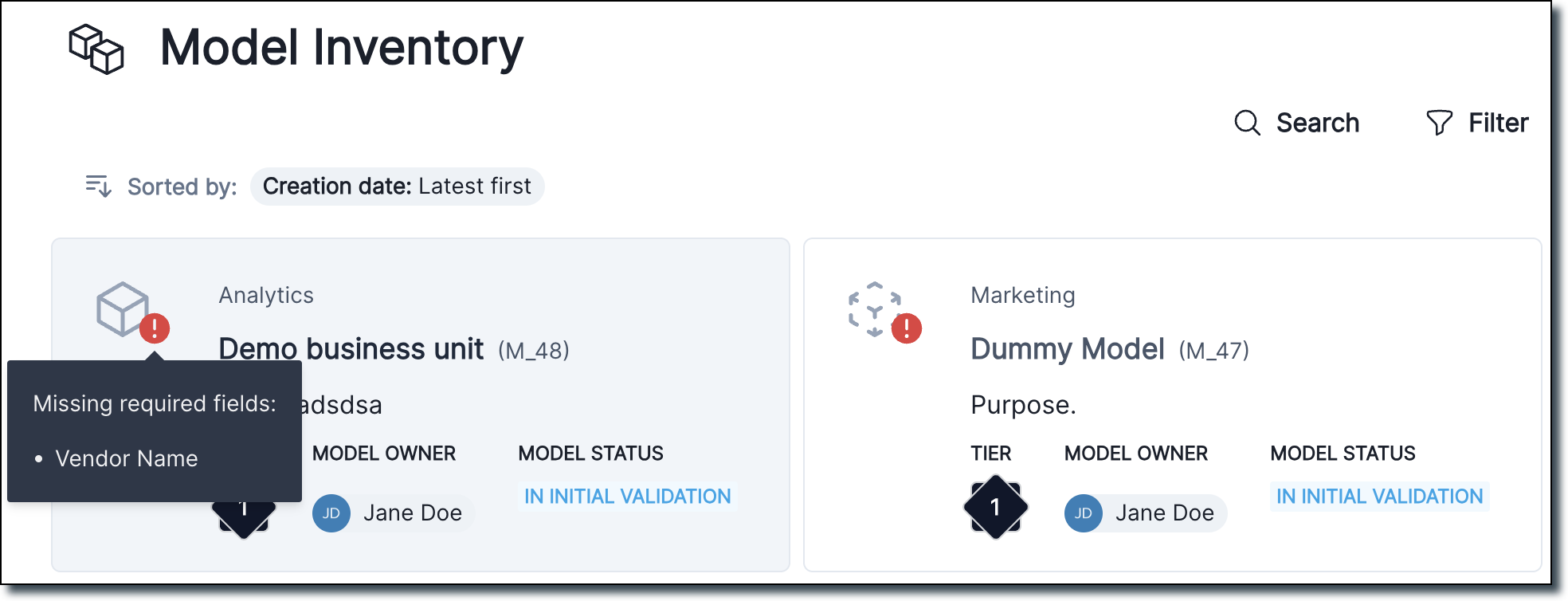
Missing required field card view
We added a tooltip for required missing fields on Inventory Model card view.
Template bug fixes
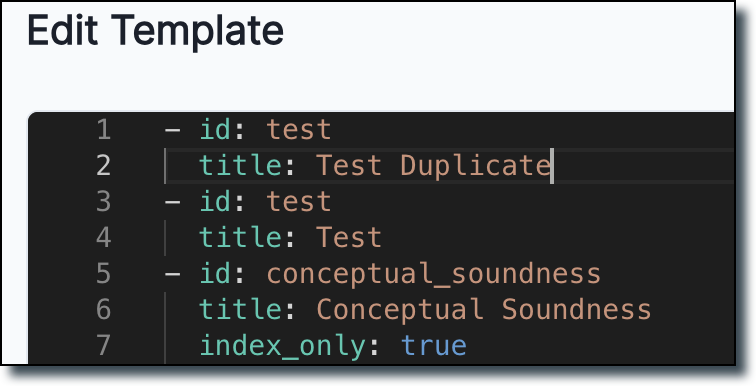
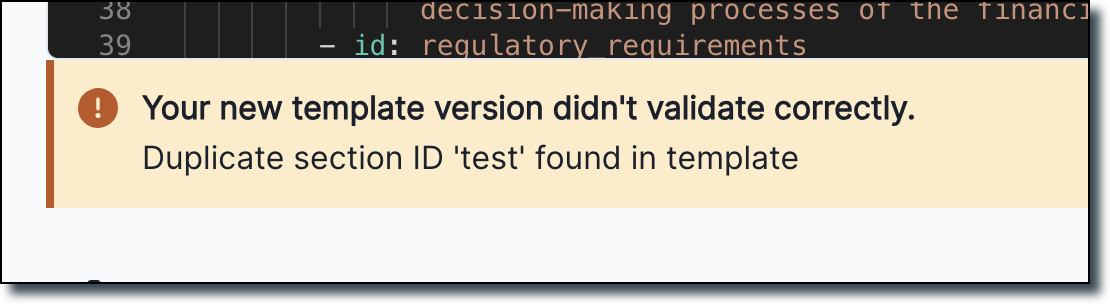
We now validate whether a template has duplicate section IDs and return an error if a duplicate ID is found.
Documentation
Improved site navigation with new “About” section
About ValidMind
We’ve revamped our documentation for a cleaner, more intuitive experience. The update features a brand new About section:
- Features includes product overviews and our glossary.
- Contributing includes community information and our new style guide.
- Releases includes our latest product updates.
- Fine print includes our data privacy policy, and our software license agreement.
Contributing
Find a brand new set of guides on contributing to our open source software. Learn how to engage with the ValidMind community, read about our brand voice and vision, and more:
- ValidMind community: You’re part of the ValidMind community. Come learn and play with us.
- ValidMind style guide: Check out the first official version of the ValidMind style guide.
ValidMind style guide
Check out the first official version of the ValidMind style guide!
- Learn about the ValidMind voice
- Understand our shared vision and goals
- See our reference for formatting conventions
More contextual information in Jupyter Notebooks
Many of our Jupyter Notebooks have received improvements to make them easier to consume and more standalone:
- Introductions now include more contextual information
- A new table of contents makes notebooks easier to navigate
- Key concepts are explained in the context where you might need that information
- Next steps make it easier to find additional learning resources
QuickStart improvements
We reworked our QuickStart experience to shorten the number of clicks it takes to get you started.
You can now access the QuickStart directly from the homepage of our docs site, where we direct you to the preferred QuickStart on JupyterHub right away.
New QuickStart video
A new three-minute video walks you through documenting a model with ValidMind and is now included in the QuickStart for JupyterHub.
Sandbox getting started
We added getting started information for the new ValidMind sandbox environment, which is currently available on request. You can use the sandbox to gain hands-on experience and explore what ValidMind has to offer.
The sandbox mimics a production environment. It includes comprehensive resources such as notebooks with sample code you can run, sample models registered in the model inventory, and draft documentation and validation reports.
Most of our model documentation features are available for you to test in the sandbox. These include:
- Automated model testing & documentation
- Preparing model validation reports
- Large language model (LLM) support
These features provide a rich context for testing and evaluation. You can use realistic models and datasets without any risk to your production environment. Learn more…