# Replace with your code snippet
import validmind as vm
vm.init(
api_host = "https://api.prod.validmind.ai/api/v1/tracking",
api_key = "...",
api_secret = "...",
project = "..."
)Run unit metrics
To turn complex evidence into actionable insights, you can run a unit metric as a single-value measure to quantify and monitor risks throughout a model’s lifecycle.
In this interactive notebook, we introduce the concept of unit metric and provide a step-by-step guide on how to define, execute and extract results from these measures. As an example, we use data from a customer churn use case to fit a binary classification model. To illustrate the application of these measures, we show you how to run sklearn classification metrics as unit metrics, demonstrating their utility in quantifying model performance and risk.
In Model Risk Management (MRM), the primary objective is to identify, assess, and mitigate the risks associated with the development, implementation, and ongoing use of quantitative models. The process of measuring risk involves the understanding and assessment of evidence generated throw multiple tests across all the model development lifecycle stages, from data collection and data quality to model performance and explainability.
Evidence versus risk
The distinction between evidence and quantifiable risk measures is a critical aspect of MRM. Evidence, in this context, refers to the outputs from various tests conducted throughout the model lifecycle. For instance, a table displaying the number of missing values per feature in a dataset is a form of evidence. It shows where data might be incomplete, which can affect the model’s performance and reliability. Similarly, a Receiver Operating Characteristic (ROC) curve is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied. The curve is evidence of the model’s classification performance.
However, these pieces of evidence do not offer a direct measure of risk. To quantify risk, one must derive metrics from this evidence that reflect the potential impact on the model’s performance and the decisions it informs. For example, the missing data rate, calculated as the percentage of missing values in the dataset, is a quantifiable risk measure that indicates the risk associated with data quality. Similarly, the accuracy score, which measures the proportion of correctly classified labels, acts as an indicator of performance risk in a classification model.
Unit metric
A Unit metric is a single value measure that is used to identify and monitor risks arising from the development of Machine Learning or AI models. This metric simplifies evidence into a single actionable number, that can be monitored and compared over time or across different models or datasets.
Properties:
- They are the fundamental computation unit that returns a single value.
- They quantify risk and can be used to monitor and assess risks associated with a model’s entire lifecycle.
- Measurable, relevant, and linked to risk areas and critical business processes - e.g., regulatory requirements, risk appetite, model performance, data quality.
- Standalone in nature, meaning they do not rely on other metrics for their calculation or interpretation.
Incorporating unit metrics into your ML workflow streamlines risk assessment, turning complex analyses into clear, actionable insights.
Contents
About ValidMind
ValidMind is a platform for managing model risk, including risk associated with AI and statistical models.
You use the ValidMind Developer Framework to automate documentation and validation tests, and then use the ValidMind AI Risk Platform UI to collaborate on model documentation. Together, these products simplify model risk management, facilitate compliance with regulations and institutional standards, and enhance collaboration between yourself and model validators.
Before you begin
This notebook assumes you have basic familiarity with Python, including an understanding of how functions work. If you are new to Python, you can still run the notebook but we recommend further familiarizing yourself with the language.
If you encounter errors due to missing modules in your Python environment, install the modules with pip install, and then re-run the notebook. For more help, refer to Installing Python Modules.
New to ValidMind?
If you haven’t already seen our Get started with the ValidMind Developer Framework, we recommend you explore the available resources for developers at some point. There, you can learn more about documenting models, find code samples, or read our developer reference.
For access to all features available in this notebook, create a free ValidMind account.
Signing up is FREE — Sign up nowKey concepts
Model documentation: A structured and detailed record pertaining to a model, encompassing key components such as its underlying assumptions, methodologies, data sources, inputs, performance metrics, evaluations, limitations, and intended uses. It serves to ensure transparency, adherence to regulatory requirements, and a clear understanding of potential risks associated with the model’s application.
Documentation template: Functions as a test suite and lays out the structure of model documentation, segmented into various sections and sub-sections. Documentation templates define the structure of your model documentation, specifying the tests that should be run, and how the results should be displayed.
Tests: A function contained in the ValidMind Developer Framework, designed to run a specific quantitative test on the dataset or model. Tests are the building blocks of ValidMind, used to evaluate and document models and datasets, and can be run individually or as part of a suite defined by your model documentation template.
Metrics: A subset of tests that do not have thresholds. In the context of this notebook, metrics and tests can be thought of as interchangeable concepts.
Custom metrics: Custom metrics are functions that you define to evaluate your model or dataset. These functions can be registered with ValidMind to be used in the platform.
Inputs: Objects to be evaluated and documented in the ValidMind framework. They can be any of the following:
- model: A single model that has been initialized in ValidMind with
vm.init_model(). - dataset: Single dataset that has been initialized in ValidMind with
vm.init_dataset(). - models: A list of ValidMind models - usually this is used when you want to compare multiple models in your custom metric.
- datasets: A list of ValidMind datasets - usually this is used when you want to compare multiple datasets in your custom metric. See this example for more information.
Parameters: Additional arguments that can be passed when running a ValidMind test, used to pass additional information to a metric, customize its behavior, or provide additional context.
Outputs: Custom metrics can return elements like tables or plots. Tables may be a list of dictionaries (each representing a row) or a pandas DataFrame. Plots may be matplotlib or plotly figures.
Test suites: Collections of tests designed to run together to automate and generate model documentation end-to-end for specific use-cases.
Example: the classifier_full_suite test suite runs tests from the tabular_dataset and classifier test suites to fully document the data and model sections for binary classification model use-cases.
Initialize the client library
ValidMind generates a unique code snippet for each registered model to connect with your developer environment. You initialize the client library with this code snippet, which ensures that your documentation and tests are uploaded to the correct model when you run the notebook.
Get your code snippet:
In a browser, log into the Platform UI.
In the left sidebar, navigate to Model Inventory and click + Register new model.
Enter the model details and click Continue. (Need more help?)
For example, to register a model with name
[Demo] Customer Churn (Unit Metrics)for use with this notebook, and select:- Documentation template:
Baseline template - Use case:
Analytics
You can fill in other options according to your preference.
- Documentation template:
Go to Getting Started and click Copy snippet to clipboard.
Next, replace this placeholder with your own code snippet:
Notebook setup
import xgboost as xgb
%matplotlib inlineLoad the demo dataset
In this example, we load a demo dataset to fit a customer churn model.
from validmind.datasets.classification import customer_churn as demo_dataset
print(
f"Loaded demo dataset with: \n\n\t• Target column: '{demo_dataset.target_column}' \n\t• Class labels: {demo_dataset.class_labels}"
)
raw_df = demo_dataset.load_data()
raw_df.head()Train a model for testing
We train a simple customer churn model for our test.
train_df, validation_df, test_df = demo_dataset.preprocess(raw_df)
x_train = train_df.drop(demo_dataset.target_column, axis=1)
y_train = train_df[demo_dataset.target_column]
x_val = validation_df.drop(demo_dataset.target_column, axis=1)
y_val = validation_df[demo_dataset.target_column]
model = xgb.XGBClassifier(early_stopping_rounds=10)
model.set_params(
eval_metric=["error", "logloss", "auc"],
)
model.fit(
x_train,
y_train,
eval_set=[(x_val, y_val)],
verbose=False,
)feature_columns = [col for col in test_df.columns if col != demo_dataset.target_column]
feature_columnsInitialize ValidMind objects
Once the datasets and model are prepared for validation, we initialize ValidMind dataset and model, specifying features and targets columns. The property input_id allows users to uniquely identify each dataset and model. This allows for the creation of multiple versions of datasets and models, enabling us to compute metrics by specifying which versions we want to use as inputs.
import validmind as vm
vm_test_ds = vm.init_dataset(
input_id="test_dataset",
dataset=test_df,
target_column=demo_dataset.target_column,
feature_columns=feature_columns,
)
vm_model = vm.init_model(model=model, input_id="my_model")Assign predictions
We can now use the assign_predictions() method from the Dataset object to link existing predictions to any model. If no prediction values are passed, the method will compute predictions automatically:
vm_test_ds.assign_predictions(
model=vm_model,
)vm_test_ds.extra_columnsRunning unit metrics
Compute F1 score
The following snippet shows how to set up and execute a unit metric implementation of the F1 score from sklearn. In this example, our objective is to compute F1 for the test dataset. Therefore, we specify vm_test_ds as the dataset in the inputs along with the metric_id.
Dataset to Metric Input Mapping
To accurately compute the F1 score, it’s essential to ensure that these columns are correctly aligned and contain the relevant data. The F1 score requires two inputs:
- the predictions
y_predand - the true labels
y_true
Since vm_test_ds has the capability to include multiple prediction columns, each linked to a different model. Therefore, it’s essential to specify both the dataset for extracting the target column and the correct prediction column, as well as the model to ensure the selection of the appropriate prediction column for that specific model, referred to as vm_model.
When calculating the F1 score, it’s essential to use the correct prediction column associated with vm_model within vm_test_ds. This prediction column is dynamically identified based on the model id, specified in input_id.
from validmind.tests import run_test
inputs = {"model": vm_model, "dataset": vm_test_ds}run_test("validmind.unit_metrics.classification.sklearn.F1", inputs=inputs)Pass parameters
When using the unit metric implementation of the F1 score from sklearn, it’s important to note that this implementation supports all parameters of the original sklearn.metrics.f1_score function. This flexibility allows you to tailor the metric computation to your specific needs and scenarios.
Below, we provide a brief description the parameters you can pass to customize the F1 score calculation:
average: Specifies the averaging method for the F1 score. Common options include ‘micro’, ‘macro’, ‘samples’, ‘weighted’, or None.sample_weight: Allows for weighting of samples. By default, it is None, but it can be an array of weights that are applied to the samples, useful for cases where some classes are more important than others.zero_division: Defines the behavior when there is a division by zero during F1 calculation. Options are ‘warn’, ‘raise’, or a numeric value like 0 or 1, indicating what value to set when encountering division by zero.
run_test(
"validmind.unit_metrics.classification.sklearn.F1",
inputs=inputs,
params={
"average": "micro",
"sample_weight": None,
"zero_division": "warn",
},
)Load the last computed value
Unit metrics are designed to optimize performance and efficiency by caching results of metric computations. When you execute a metric with the same signature —a unique combination of the metric ID, model, inputs, and parameters- a second time, validmind retrieves the result from its last computed value instead of recalculating it. This feature ensures faster access to metrics you’ve previously run and conserves computational resources.
First computation of precision metric
In this first example, the precision metric is computed for the first time with a specific dataset. The result of this computation is stored in the cache.
run_test("validmind.unit_metrics.classification.sklearn.Precision", inputs=inputs)Second computation with the same signature
In this second example, the same precision metric computation is requested again with the identical inputs. Since the signature (metric ID and inputs) matches the previous run, validmind loads the result directly from the cache instead of recomputing it.
run_test("validmind.unit_metrics.classification.sklearn.Precision", inputs=inputs)Computation with a changed signature
In this example, the signature is modified by adding parameters. This change prompts validmind to compute the metric anew, as the new signature does not match any stored result. The outcome is then cached, ready for any future requests with the same signature.
run_test(
"validmind.unit_metrics.classification.sklearn.Precision",
inputs=inputs,
params={
"average": "micro",
"sample_weight": None,
"zero_division": "warn",
},
)Unit metrics for model performance
run_test("validmind.unit_metrics.classification.sklearn.Accuracy", inputs=inputs)run_test("validmind.unit_metrics.classification.sklearn.Recall", inputs=inputs)run_test("validmind.unit_metrics.classification.sklearn.ROC_AUC", inputs=inputs)Composing Complex Metrics from Individual Unit Metrics
Run multiple unit metrics as a single test
Up until now we have just been running individual unit metrics on their own. However, in a normal use-case, you will likely want to compose multiple unit metrics into a more complex metric. For instance, we may want to compose the above metrics (f1_score, precision, recall, accuracy and roc_auc) into a single tabular display showing the overall model performance. This can be done by using the run_test function. This will allow us to run all these metrics at the same time, display the results in a single output, customize the output using html templates, and finally save the result as a single composite metric to the ValidMind platform. Let’s see how we can do this.
result = run_test(
name="Model Performance",
unit_metrics=[
"validmind.unit_metrics.classification.sklearn.F1",
"validmind.unit_metrics.classification.sklearn.Precision",
"validmind.unit_metrics.classification.sklearn.Recall",
"validmind.unit_metrics.classification.sklearn.Accuracy",
"validmind.unit_metrics.classification.sklearn.ROC_AUC",
],
inputs=inputs,
)If we take a look at the result_id for the result, we’ll see that it is a unique identifier that starts with validmind.composite_metric.<user-supplied-metric-name>. This will be used to identify this result as coming from a composite metric and is used to rebuild the composite metric as we will see in the next section.
result.result_idLet’s go ahead and log the result to save it to the ValidMind platform.
result.log()Adding composite metrics to the documentation template
Now that we have run and logged the composite metric, the result and the metadata required to reconstruct the composite metric that was run is all stored in the ValidMind platform. You can now visit the documentation project that you connected to at the beginning of this notebook and add a new content block in the relevant section.
To do this, go to the documentation page of your model [Demo] Customer Churn (Unit Metrics) - Initial Validation project and navigate to the Model Development -> Model Evaluation section. Then hover between any existing content block to reveal the + button as shown in the screenshot below.

Click on the + button and select Test-Driven Block. This will open a window where you can select the ModelPerformance test. This will show a preview of the composite metric and it should match the results shown above.
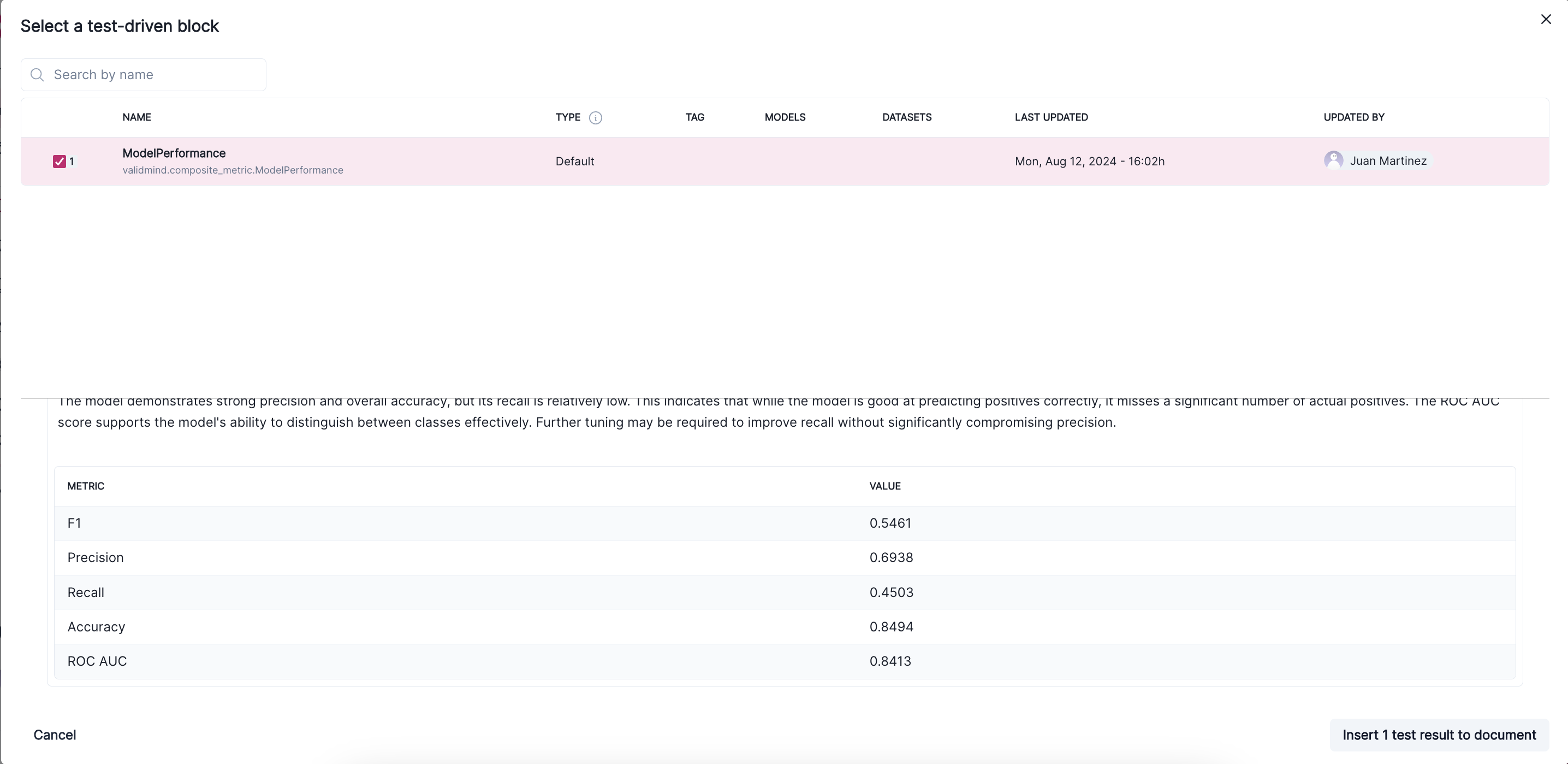
Finally, click on the Insert block button to add the composite metric to the documentation. You’ll see the composite metric displayed in the documentation and now anytime you run run_documentation_tests(), the Model Performance composite metric will be run as part of the test suite. Let’s go ahead and connect to the documentation project and run the tests.
Reload the Documentation Project Template
You can call vm.reload() to re-intialize the connection the ValidMind platform. This will refresh any changes made to the documentation template.
vm.reload()Now that we have reconnected, we can run vm.preview_template() to see that our new composite metric has been added to the documentation.
vm.preview_template()You should see this in the above output:
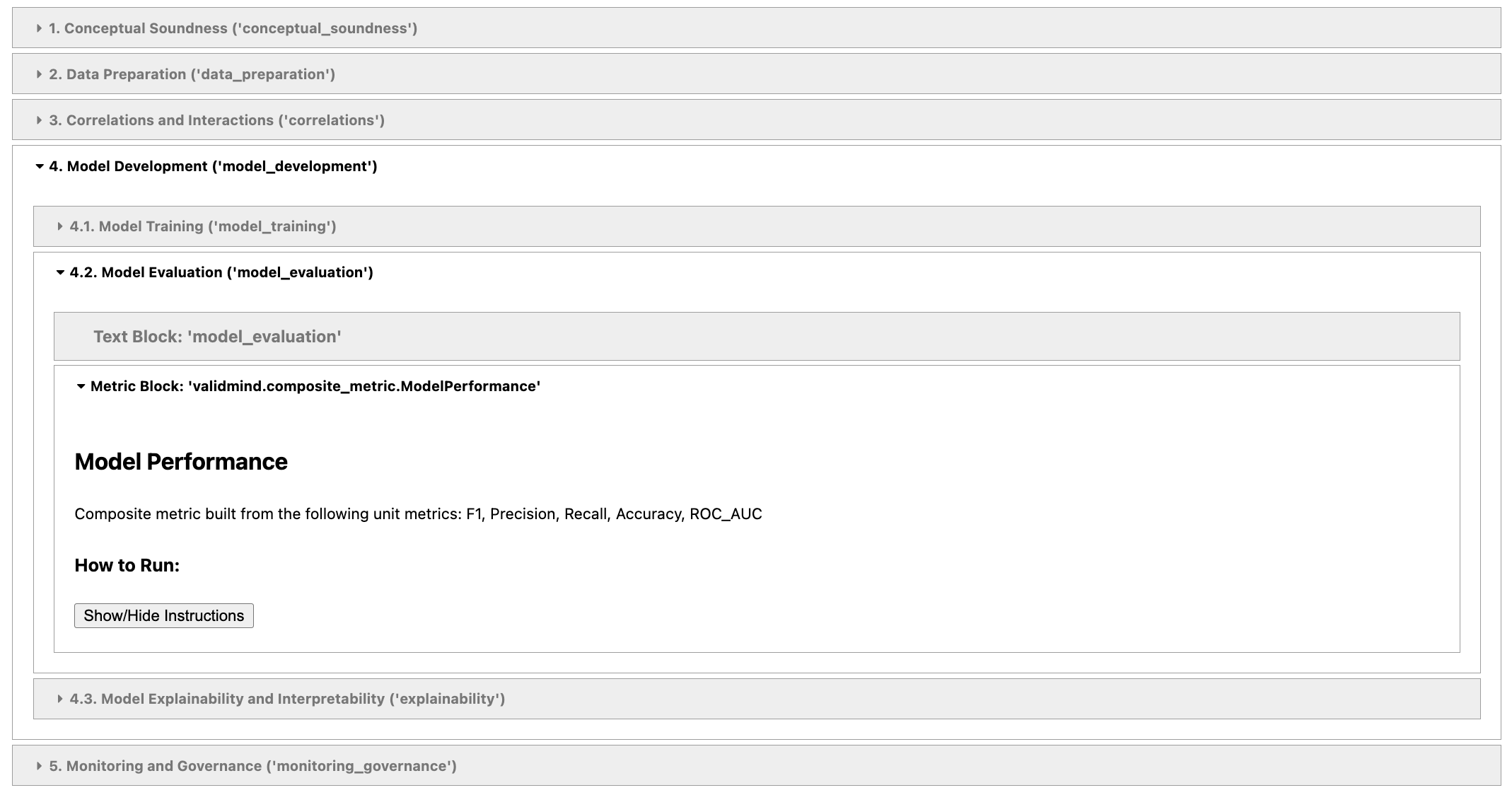
Let’s go ahead and run vm.run_documentation_tests() to run the model_evaluation section of the documentation that includes the Model Performance composite metric that we just added. You should see the result in the output as well as in the documentation page on the ValidMind platform.
res = vm.run_documentation_tests(
inputs=inputs,
section="model_evaluation",
)Next steps
You can look at the results of this test suite right in the notebook where you ran the code, as you would expect. But there is a better way — use the ValidMind platform to work with your model documentation.
Work with your model documentation
From the Model Inventory in the ValidMind Platform UI, go to the model you registered earlier.
Click and expand the Model Development section.
What you see is the full draft of your model documentation in a more easily consumable version. From here, you can make qualitative edits to model documentation, view guidelines, collaborate with validators, and submit your model documentation for approval when it’s ready. Learn more …
Discover more learning resources
We offer many interactive notebooks to help you document models:
Or, visit our documentation to learn more about ValidMind.